Ce texte est la traduction française de la transcription de la présentation que j’ai faite le 22 avril 2024 à la séance « Quand les sciences sociales rencontrent la génomique » du séminaire « Les sciences sociales en question : grandes controverses épistémologiques et méthodologiques » à Sciences Po Paris. J’y ai inséré des images de mes diapos. La transcription intégrale (en anglais) du séminaire est disponible ici.
Commençons par ce que j’appelle le résultat le plus important de la sociologie de l’éducation, à savoir l’influence du statut socioéconomique de la famille sur la réussite scolaire des enfants. Je montre ici un résultat particulier, qui provient des études PISA menées par l’OCDE, mais en principe, toute étude qui recueille des informations à la fois sur le contexte familial et sur les résultats scolaires trouve cette relation. La corrélation est d’environ 0,3-0,4, et c’est probablement le résultat le mieux répliqué en sociologie de l’éducation.

Ce résultat est largement interprété comme reflétant un effet causal de l’environnement fourni par les parents sur les résultats scolaires de leurs enfants. Bien sûr, c’est une interprétation très plausible et personne ne la conteste vraiment. Cependant, j’aimerais attirer votre attention sur le fait qu’il ne s’agit que d’une corrélation. Si vous êtes un spécialiste des sciences sociales qui s’inquiète de la distinction entre causalité et corrélation, vous avez intérêt à être un peu prudent. En particulier, si vous êtes attentif à la différence entre causalité et corrélation, vous devriez vous soucier des facteurs de confusion. Je suis sûr que c’est le cas dans vos propres études.
Il y a là une corrélation entre certaines caractéristiques des parents et certaines caractéristiques de leurs enfants. Le problème est qu’il existe un facteur de confusion majeur: le génome. En effet, les parents ont un génome qui influence leur propre devenir, et la moitié de ce génome est transmis à leurs enfants, où il peut produire des effets similaires, ce qui entraîne une similitude entre les caractéristiques des parents et celles des enfants, indépendamment de l’environnement. Cela implique un deuxième chemin de causalité potentiel entre les caractéristiques parentales et les caractéristiques des enfants. Cette corrélation peut effectivement refléter une causalité environnementale, mais pas seulement. Si nous ne prenons pas en compte le chemin causal génétique, nous ne pouvons pas savoir si une causalité environnementale est prouvée.
C’est donc la première mise en garde que je souhaite soulever : en sciences sociales, nous passons parfois de la corrélation à la causalité sans tenir compte des facteurs génétiques. Un tel saut n’est pas toujours légitime.
En termes de résultats scolaires, je vais surtout parler du niveau d’études : c’est le résultat final du parcours scolaire, le diplôme le plus élevé que les gens obtiennent. C’est très simple à mesurer. Mais bien sûr, vous pouvez aussi le remplacer par toute autre mesure du niveau d’études ou de la performance scolaire. N’importe quelle note à un examen ou à un test fera l’affaire, les mêmes résultats sont généralement valables pour toutes les mesures éducatives.
Le niveau d’études d’un enfant est évidemment influencé par ses propres caractéristiques individuelles telles que ses capacités cognitives, sa motivation, son comportement, ses efforts, etc. Si l’on regarde un peu en amont, quelles sont les causes des caractéristiques de cet enfant ? Il existe deux catégories de causes : les gènes et l’environnement.

Donc, en principe, si vous avez échantillonné toutes les causes ultimes possibles dans le génome de l’enfant et dans son environnement, vous disposez de toutes les causes potentielles de ses traits cognitifs et comportementaux et, en fin de compte, de son niveau d’études.
Si vous regardez maintenant l’environnement de l’enfant, vous savez qu’il est façonné dans une large mesure par les parents et qu’il est influencé en particulier par le niveau d’éducation et les ressources parentales. Nous combinons généralement ces deux mesures (parfois avec la catégorie professionnelle) en une variable que nous appelons le statut socioéconomique. Il est bien connu que le statut socioéconomique façonne l’environnement de l’enfant et qu’il a une influence sur son niveau d’études. Comme je l’ai dit, la taille de la corrélation se situe entre 0,3 et 0,5.
Un peu plus en amont, le statut socio-économique des parents a été influencé par leurs propres capacités cognitives, et ces capacités ont elles-mêmes été influencées par leur environnement et par leurs gènes. Ces derniers ont été transmis à leurs enfants. C’est le deuxième chemin causal. Ainsi, chaque fois que vous mesurez cette corrélation entre le statut socio-économique et le niveau d’études, elle peut être médiée par la voie environnementale, mais elle peut aussi refléter le chemin causal alternatif, par les gènes des parents qui influencent à la fois le statut socio-économique des parents et les gènes de l’enfant et donc ses capacités cognitives et son niveau d’éducation.
Il s’avère que certaines études génomiques ont suggéré que ce chemin alternatif représentait environ 50 % de la corrélation entre le statut socio-économique et le niveau d’éducation. Cela ne remet pas en cause l’idée d’une causalité par l’environnement familial, elle existe bel et bien, mais elle peut être surestimée par la corrélation brute. Si l’on tient compte correctement de la transmission génétique, on obtient une estimation révisée de la voie environnementale, réduite de moitié environ. Étant donné que la médiation génétique représente environ la moitié de l’effet, il est très important d’en tenir compte.
J’ai dévoilé un des principaux résultats, mais je suis parfaitement conscient que vous n’êtes pas obligé de me croire sur parole. Vous êtes en droit de demander des données avant de me croire, et le temps est très court, donc je ne vais pas pouvoir vous montrer toutes les données pertinentes, mais je vais me référer aux principales sources de données et vous montrer quelques éléments, avec des indications pour ceux qui veulent aller plus loin.
Pourquoi faut-il croire que la génétique influence la performance scolaire et le niveau d’études ? Il existe trois sources principales de preuves.

Le premier type de données probantes est celui des études familiales. Les plus connues sont les études sur les jumeaux, qui existent depuis près d’un siècle, mais aussi les études d’adoption, et il existe également d’autres types de modèles utilisant des données familiales. Le deuxième type d’études est celui des mutations génétiques, et le troisième type est celui des études génomiques. Je vais illustrer chacune d’elles.
Premièrement, les études familiales. Comme vous le savez, il existe des jumeaux monozygotes, qui sont génétiquement identiques, et des jumeaux dizygotes, qui ne sont génétiquement similaires qu’à 50 %. Ces barres montrent les corrélations des scores à divers tests ou questionnaires au sein de paires de jumeaux : les jumeaux monozygotes en noir et les paires dizygotes en barres hachurées.

Comme vous pouvez le constater, les barres noires sont toujours plus hautes que les barres hachurées, ce qui signifie que les jumeaux identiques sont toujours plus semblables que les jumeaux dizygotes. Cela est généralement interprété comme une preuve d’influences génétiques et est utilisé pour calculer ce que nous appelons l’héritabilité.
Il faut noter que certains de ces traits sont pertinents pour les résultats scolaires, comme l’intelligence générale, le raisonnement verbal, la mémoire. Il y a aussi la réussite scolaire à l’adolescence, donc cela doit être une note à un examen au lycée. Il y a même les centres d’intérêts professionnels.
Ce graphique vous montre le même résultat que dans toutes les études sur les jumeaux, à savoir que tout ce que vous pouvez mesurer chez un individu semble être héritable dans une certaine mesure, y compris les scores cognitifs et scolaires.
Je sais que les études sur les jumeaux ont été fortement critiquées, on peut y revenir si vous le souhaitez, mais il est important de savoir qu’elles ne sont pas isolées. D’abord, elles ont été très bien répliquées. Ensuite, elles sont complétées par des études d’adoption qui ont des hypothèses et des méthodes différentes mais qui donnent des résultats très similaires.
Maintenant, toutes ces études familiales nous permettent de quantifier l’héritabilité, c’est-à-dire qu’il y a des influences génétiques, mais c’est très vague. Une fois que vous savez qu’il y a des gènes impliqués, vous aimeriez savoir : lesquels et comment fonctionnent-ils ?
Notre compréhension initiale des gènes s’appuyait en grande partie sur des études sur les mutations génétiques. Cela remonte à l’identification de la cause génétique du syndrome de Down, causé par une copie supplémentaire du chromosome 21.
Bien qu’il s’agisse d’un exemple clair de mutation génétique, de nombreuses autres mutations moins spectaculaires ont été découvertes depuis. Actuellement, nous connaissons plus de 1 000 gènes, sur un total d’environ 25 000, dont les mutations peuvent entraîner une forme de déficience intellectuelle.
Il est important de noter que ces mutations ne se limitent pas à provoquer des déficiences intellectuelles. Elles peuvent également entraîner d’autres troubles, comme des troubles du langage et de la lecture. Ces mutations sont toutefois assez rares, affectant environ 1 % de la population.

Il est intéressant de noter que bon nombre de ces gènes ont été découverts dans ce que l’on appelle des familles multiplexes. Dans ces familles, plusieurs membres de générations différentes sont touchés par un trouble particulier. Les hommes sont représentés par des carrés, les femmes par des cercles et les personnes atteintes du trouble sont indiquées en noir.
Prenons par exemple cette famille où la grand-mère souffrait d’un trouble du langage. Quatre de ses cinq enfants et environ 50 % de ses petits-enfants souffrent également de ce trouble du langage. De même, dans une famille française que j’ai étudiée, le grand-père souffrait de dyslexie, un trouble de la lecture, et huit de ses 11 enfants et environ 50 % de ses petits-enfants souffrent également de dyslexie.
En étudiant le génome de ces familles multiplexes, nous pouvons, avec un peu de chance, trouver une mutation qui peut être associée de manière fiable à la transmission du trouble. Cette méthode a été utilisée pour découvrir de nombreux gènes associés à des traits cognitifs. Il convient toutefois de noter que cela ne s’applique qu’à une petite fraction des personnes atteintes de troubles du langage ou de dyslexie. La plupart d’entre elles ne sont porteuses d’aucune mutation identifiable (pour l’instant).
Enfin, il va sans dire que les personnes atteintes de déficiences intellectuelles, de troubles du langage ou de troubles de la lecture sont souvent confrontées à des difficultés dans le cadre scolaire. Globalement, tous ces gènes contribuent aux variations du niveau de scolarité.
Si les mutations rares ont fait l’objet de nombreuses recherches en génétique, il est important de prendre en compte la population dans son ensemble. Plus précisément, nous devons nous demander si des variations plus fréquentes dans le génome pourraient expliquer les variations plus fréquentes dans les résultats scolaires chez les personnes qui ne présentent pas de troubles évidents ni de mutations délétères.
Pour répondre à cette question, nous nous tournons vers l’analyse du génome entier. Je vais illustrer cela avec une étude d’association pangénomique (GWAS) tirée d’un article de 2022. Dans un GWAS, des échantillons d’ADN sont prélevés auprès des participants, généralement via des échantillons de salive ou de sang. Dans l’étude à laquelle je fais référence, ils ont inclus un nombre impressionnant de 3 000 000 de participants. Ce résultat a été obtenu en fusionnant des études génétiques précédentes, quels que soient leur objectif initial. La plupart des études génétiques sont menées pour étudier la génétique du cancer, du diabète, des troubles psychiatriques, etc., et la plupart des participants sont également interrogés sur leur diplôme le plus élevé. En réutilisant et en regroupant ces données provenant de toutes les sources de données possibles dans le monde entier, ils ont réussi à mener une étude sur la génétique du niveau d’études avec 3 000 000 de participants.

Le génome est examiné sur environ 500 000 à 1 000 000 de sites. Il s’agit de polymorphismes nucléotidiques (SNP), des sites de l’ADN où l’on peut trouver l’un des quatre nucléotides : ACGT. L’association de chacun de ces SNP avec le phénotype est testée statistiquement. Pour chacun de ces SNP, nous savons s’il est statistiquement associé au phénotype et nous connaissons la taille de l’effet.
Étant donné la difficulté de gérer 1 000 000 de variables, les chercheurs calculent des scores polygéniques (PGS, GPS ou PRS). Un score polygénique résume toutes les informations sur tous ces polymorphismes d’ADN. Pour chaque site, la taille de l’effet de ce SNP sur le résultat est calculée. Par exemple, ici, avoir un C au lieu d’un A modifie le niveau d’éducation de -0,02 écart type, et ainsi de suite pour chaque site.
Les résultats GWAS de chaque personne sont pris en compte et si elle a une copie de C ici, son score est incrémenté de -0,02. Si elle a deux copies de G là et que la taille de l’effet de G est de +0,01, alors son score est augmenté de 0,02, et ainsi de suite. Au final, vous additionnez les effets de tous les SNP et vous obtenez le score polygénique, qui quantifie la prédisposition génétique globale de l’individu pour ce phénotype.
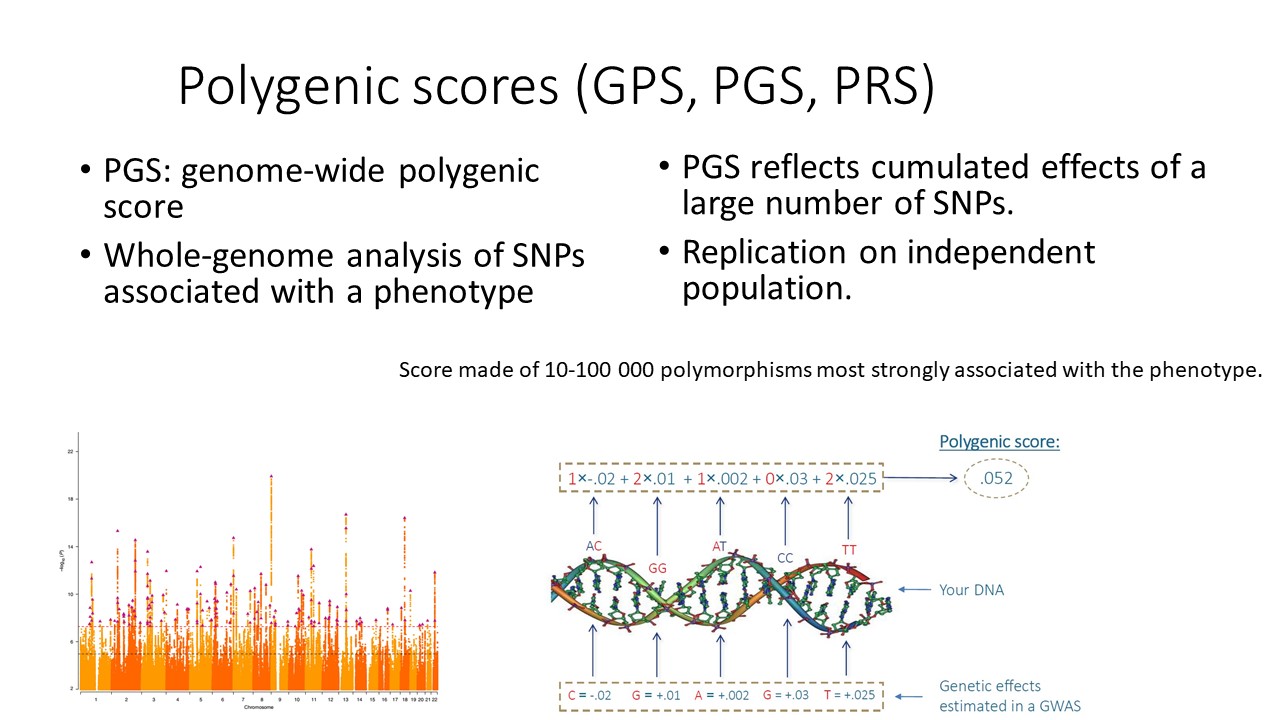
En général, le score polygénique prédit beaucoup moins de variance que tous les SNP du génome, mais on peut néanmoins prédire une quantité significative de variance, comme 5 % de la variance, ou 10 % de la variance, voire plus si on a de la chance. Dans cette étude, ils ont obtenu un score polygénique qui expliquait entre 12 et 16 % de la variance du niveau d’études, ce qui est considérable.
Pour illustrer ce type d’effet, prenons la prévalence du redoublement. Les élèves qui ont les 10 % de scores polygéniques les plus bas ont environ 30 % de risque de redoubler une classe, tandis que ceux qui se situent dans les 10 % de scores polygéniques les plus élevés ont environ 5 % de risque de redoubler une classe.
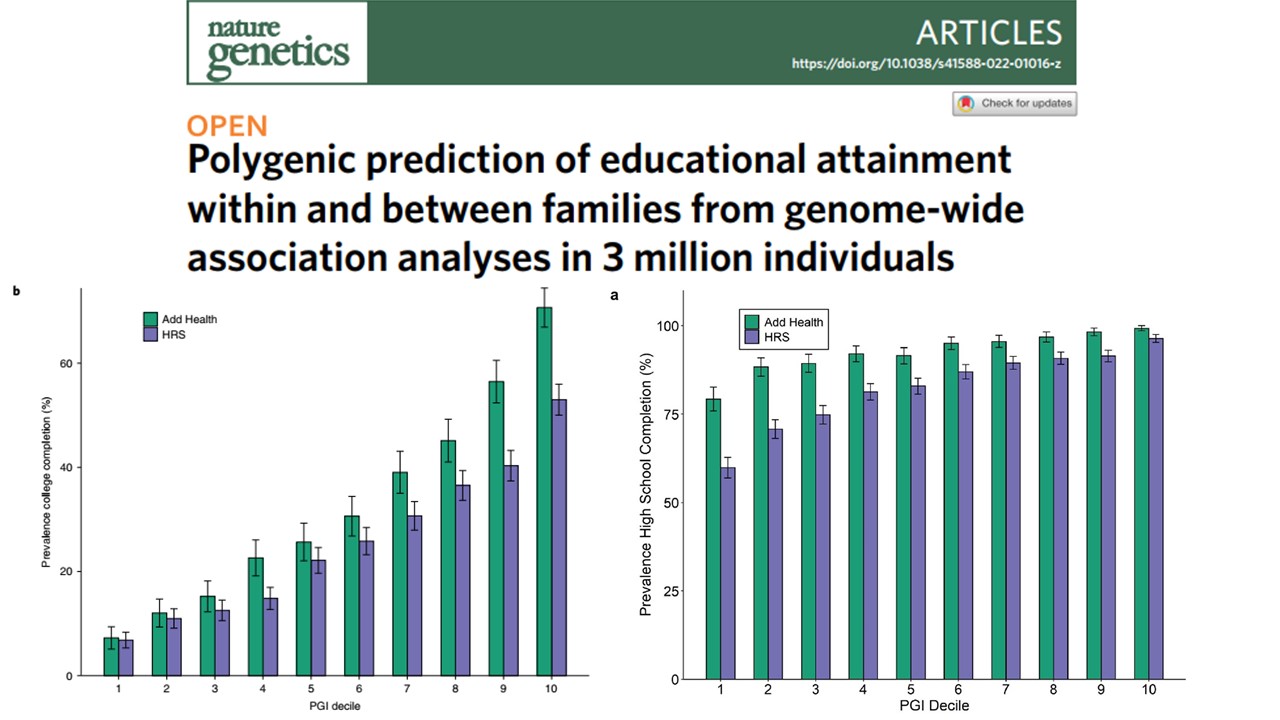
Connaître votre score polygénique ne détermine pas vraiment votre niveau d’éducation, ce n’est pas une très bonne prédiction individuelle. Mais si vous faites la moyenne sur les déciles de la population, vous pouvez voir à quel point l’effet est important. De même, si vous regardez le pourcentage de ceux qui finissent le lycée, il est d’environ 70 % dans le premier décile et de plus de 90 % dans le 10e décile. Si vous regardez le pourcentage de ceux qui obtiennent un diplôme de l’enseignement supérieur, il est d’environ 5 % dans le premier décile et de 60 % dans le 10e décile. Les scores polygéniques expliquent donc une partie des résultats scolaires.
Certains pourraient soutenir qu’un score polygénique expliquant seulement 12 % de la variance est négligeable. Cependant, lorsqu’on le compare à la variance expliquée par des variables sociales bien connues, telles que le niveau d’éducation de la mère et du père, qui expliquent chacun 15 % de la variance, ou le revenu du ménage, qui explique environ 7 % de la variance, il est clair que votre score polygénique, qu’il explique 10 %, 12 % ou 16 %, est du même ordre. Par conséquent, il doit être pris aussi au sérieux que toute variable sociale jugée importante.

Voici une étude qui examine l’impact combiné du revenu du père et du score polygénique du niveau d’étude sur l’obtention d’un diplôme universitaire. Les données sont représentées sur un graphique avec deux échelles sur l’axe des x : les quatre quartiles du revenu du père et les quatre quartiles du score polygénique. Comme prévu, un revenu paternel plus élevé est corrélé à un taux plus élevé d’obtention d’un diplôme universitaire. Cependant, au sein de chaque quartile de revenu, l’effet des différents scores polygéniques est également visible.

Cela montre les effets additifs du revenu du père et du score polygénique. Cela souligne qu’il n’y a pas de conflit entre les effets génétiques et sociaux. Si vous mesurez et analysez les deux, vous pouvez voir que les deux sont présents et contribuent conjointement au résultat.
Cette nouvelle étude explore les applications potentielles de ces résultats. L’une de ces applications est le sujet d’actualité de l’impact de l’exposition aux écrans sur le développement cognitif de l’enfant. L’hypothèse dominante est que l’exposition aux écrans affecte négativement le développement cognitif et la réussite scolaire. De nombreuses études soutiennent cette hypothèse, montrant une corrélation négative entre l’exposition aux écrans et ces variables.
D’autres hypothèses existent cependant. L’une d’elles est que les enfants dotés de certaines capacités cognitives seraient plus ou moins attirés par les appareils numériques, ce qui impliquerait une causalité inverse. Une autre hypothèse est que cette corrélation soit expliquée par des facteurs de confusion, comme le statut socioéconomique. Les différences d’exposition aux écrans pourraient être attribuées aux différences d’environnement familial et à leurs effets sur le temps passé par l’enfant devant un écran.

Si ces facteurs de confusion ne sont pas pris en compte, la corrélation entre l’exposition aux écrans et les capacités cognitives pourrait être mal interprétée. La plupart des sociologues savent que, pour interpréter correctement les données, il est important de contrôler le statut socioéconomique et les facteurs connexes. Mais ce ne sont pas les seuls facteurs de confusion possibles. Les enfants fortement exposés aux écrans peuvent également être génétiquement différents de ceux qui y sont moins exposés. Il serait donc prudent de contrôler la transmission génétique.
Malheureusement, la plupart des études ne le font pas. Cependant, une étude réalisée par des chercheurs suédois le fait. Ils ont utilisé la cohorte ABCD d’adolescents américains et ont mesuré trois types d’exposition aux écrans : regarder des vidéos, interagir sur les réseaux sociaux et jouer. Ils ont également recueilli des résultats cognitifs et éducatifs ainsi que des données génétiques.

Leurs résultats reproduisent la corrélation négative habituelle entre l’exposition aux écrans et les capacités cognitives. Cependant, ils ont également constaté que le statut socioéconomique et le score polygénique des capacités cognitives étaient corrélés négativement avec l’exposition aux écrans. Cela suggère que les deux variables devraient être ajustées dans tout modèle causal.
Dans leur étude, ils ont construit un modèle causal pour prédire les effets de différentes mesures du temps passé devant un écran sur les changements de scores d’intelligence entre deux temps. Après avoir ajusté le statut socio-économique et le score polygénique cognitif, ils ont découvert que derrière la corrélation initialement négative se cachait un effet légèrement positif ! (NB: cette étude est maintenant expliquée plus en détail dans un article dédié)
Il ne s’agit là que d’une étude et elle doit être répliquée. Elle nous rappelle toutefois l’importance de tenir compte des variables confondantes, notamment génétiques. Ne pas le faire pourrait conduire à des conclusions erronées. Ce n’est qu’un exemple de la manière dont ces résultats peuvent être appliqués, et il existe de nombreuses autres applications potentielles à envisager.
Permettez-moi de vous donner un autre exemple hypothétique, dans lequel vous voudriez comparer les effets de la scolarisation dans des écoles privées ou alternatives comme Montessori et dans des écoles publiques classiques. Bien sûr, les élèves des deux types d’écoles peuvent différer considérablement dans diverses mesures de performance scolaire, mais vous savez bien qu’il peut y avoir des facteurs de confusion. Il ne serait pas approprié d’estimer les effets de l’enseignement privé sans d’abord contrôler le statut socio-économique.
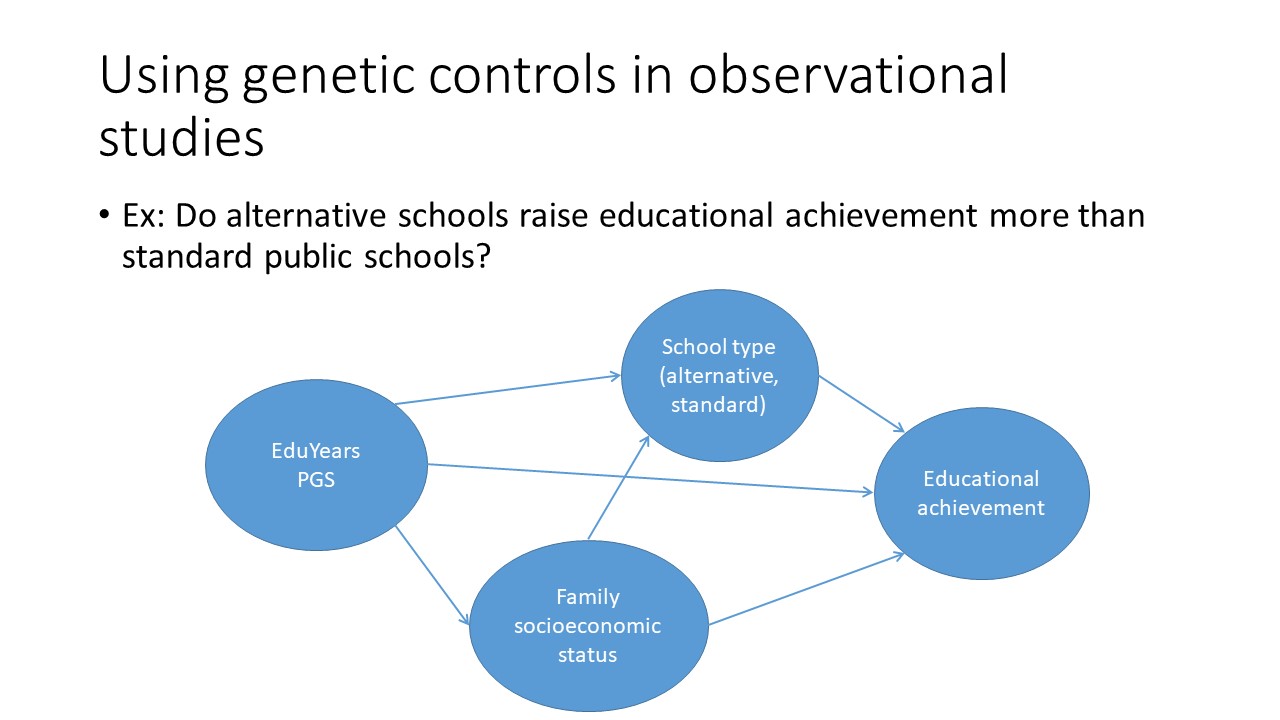
Là encore, dans une telle situation, il faut également tenir compte des facteurs génétiques confondants. Les enfants qui fréquentent les écoles publiques et privées peuvent avoir des prédispositions génétiques différentes, ce qui pourrait influencer leurs résultats scolaires.
Même dans le cadre d’une recherche interventionnelle, comme un essai contrôlé randomisé (ECR), il peut être important de s’assurer que les deux groupes comparés ne diffèrent pas significativement en termes de statut socioéconomique ou de prédispositions génétiques. Ces facteurs pourraient avoir un impact sur les résultats de l’ECR.

Il peut également y avoir des interactions au sens statistique. Par exemple, si le statut socioéconomique et les scores polygéniques peuvent avoir des effets additifs, ce n’est pas toujours le cas. De nombreuses interventions éducatives et sociales semblent fonctionner en moyenne, mais leurs résultats varient. Tous les élèves ne répondent pas aux mêmes interventions pédagogiques, ou encore on sait bien que tous les élèves dyslexiques ne répondent pas bien à la remédiation orthophonique.

Une hypothèse est que les prédispositions génétiques des individus pourraient expliquer pourquoi ils réagissent différemment à certains facteurs environnementaux ou interventions. Il pourrait donc être utile d’utiliser des scores polygéniques pour comprendre pourquoi les individus réagissent différemment à ces interventions.
En conclusion, il n’y a pas d’opposition ni de contradiction entre facteurs sociaux et facteurs génétiques. Le génome est un facteur de confusion majeur des influences sociales, et il est important d’en tenir compte dans toute étude observant des corrélations entre parents et enfants, ainsi que dans les études comparant des groupes. Il est possible de contrôler la transmission génétique dans les études sur les facteurs sociaux avec des données et une méthodologie appropriées. En outre, le génome peut également interagir avec les facteurs sociaux, ce qui élargit la portée et la complexité des modèles causaux que nous devrions prendre en compte.

Avec la baisse du coût du génotypage et la disponibilité croissante de bases de données contenant des données sur les enfants ou les adultes, y compris des données génétiques avec des résultats sociaux et éducatifs, il devient de plus en plus possible de répondre aux questions avec des contrôles génétiques appropriés. Même si vous ne collectez pas vous-même ces données, vous pourrez peut-être trouver la bonne base de données pour répondre de manière fiable à votre question.

Références
Je réalise tardivement que, contrairement à mes habitudes, ce texte manque de références. C’est parce qu’il s’agit de la transcription d’un exposé oral, les références étaient sur les diapos. Pour faciliter les recherches, je colle ci-dessous les références citées. Si vous avez des questions sur quel résultat justifie quelle affirmation, n’hésitez pas à demander des précisions en commentaire.
Galaburda, A. M., LoTurco, J., Ramus, F., Fitch, R. H., & Rosen, G. D. (2006). From genes to behavior in developmental dyslexia. Nature Neuroscience, 9(10), Article 10. https://doi.org/10.1038/nn1772
Krapohl, E., Hannigan, L. J., Pingault, J.-B., Patel, H., Kadeva, N., Curtis, C., Breen, G., Newhouse, S. J., Eley, T. C., O’Reilly, P. F., & Plomin, R. (2017). Widespread covariation of early environmental exposures and trait-associated polygenic variation. Proceedings of the National Academy of Sciences, 114(44), 11727–11732.
Lai, C. S., Fisher, S. E., Hurst, J. A., Vargha-Khadem, F., & Monaco, A. P. (2001). A forkhead-domain gene is mutated in a severe speech and language disorder. Nature, 413, 519–523.
Lee, J. J., Wedow, R., Okbay, A., Kong, E., Maghzian, O., Zacher, M., Nguyen-Viet, T. A., Bowers, P., Sidorenko, J., Linnér, R. K., Fontana, M. A., Kundu, T., Lee, C., Li, H., Li, R., Royer, R., Timshel, P. N., Walters, R. K., Willoughby, E. A., … Cesarini, D. (2018). Gene discovery and polygenic prediction from a genome-wide association study of educational attainment in 1.1 million individuals. Nature Genetics, 50(8), 1112–1121. https://doi.org/10.1038/s41588-018-0147-3
OECD. (2023). PISA 2022 Results (Volume I): The State of Learning and Equity in Education. Organisation for Economic Co-operation and Development. https://www.oecd-ilibrary.org/education/pisa-2022-results-volume-i_53f23881-en
Okbay, A., Wu, Y., Wang, N., Jayashankar, H., Bennett, M., Nehzati, S. M., Sidorenko, J., Kweon, H., Goldman, G., Gjorgjieva, T., Jiang, Y., Hicks, B., Tian, C., Hinds, D. A., Ahlskog, R., Magnusson, P. K. E., Oskarsson, S., Hayward, C., Campbell, A., … Young, A. I. (2022). Polygenic prediction of educational attainment within and between families from genome-wide association analyses in 3 million individuals. Nature Genetics, 54(4), Article 4. https://doi.org/10.1038/s41588-022-01016-z
Papageorge, N. W., & Thom, K. (2020). Genes, Education, and Labor Market Outcomes : Evidence from the Health and Retirement Study. Journal of the European Economic Association, 18(3), 1351‑1399.
Plomin, R., Owen, M. J., & McGuffin, P. (1994). The genetic basis of complex human behaviors. Science, 264(5166), 1733-1739.
Sauce, B., Liebherr, M., Judd, N., & Klingberg, T. (2022). The impact of digital media on children’s intelligence while controlling for genetic differences in cognition and socioeconomic background. Scientific Reports, 12(1), Article 1. https://doi.org/10.1038/s41598-022-11341-2
Teasdale, T. W., & Owen, D. R. (1981). Social class correlations among separately adopted siblings and unrelated individuals adopted together. Behavior Genetics, 11(6), 577–588.
Trzaskowski, M., . . . Plomin, R. (2014). Genetic influence on family socioeconomic status and children’s intelligence. Intelligence, 42, 83-88.
Von Stumm, S., Smith‐Woolley, E., Ayorech, Z., McMillan, A., Rimfeld, K., Dale, P. S., & Plomin, R. (2020). Predicting educational achievement from genomic measures and socioeconomic status. Developmental Science, 23(3), 1–8. https://doi.org/10.1111/desc.12925

Bonjour monsieur Franck Ramus,
Nous passons souvent, en sciences de l’éducation et de la formation, mais aussi parfois en sociologie et en psychologie, voir même en économie, comme on le faisait avant en médecine, de la corrélation à la causalité sans prendre les précautions élémentaires maintenant bien connues : l’expérimentation comparative randomisée, en double aveugle, en terrain ouvert et multicentrique. Essayer de prendre aussi en compte un facteur génétique, ou bien encore un autre, ne suffira pas. Comme il n’est pas possible d’attribuer aléatoirement une CSP à un apprenant, la répétition des études dans des conditions originales nous permet d’avancer. Une étude au moins a été menée sur des jumaux séparés à la naissance aux USA; c’est un bon exemple.
Faire des ECR n’est pas facile mais cela existe, certains EC y arrivent (comme P Bressoux), certains thésards y sont parvenus (comme S. Pinazo, seule thèse observée en 35 ans en sciences de l’éducation s’appuyant sur une méthodologie « gold standard » méthodologie que j’ai supervisée directement).
Il existe aussi une grille de lecture canadienne qui indique bien que, comme en médecine, comme en économie du développement (Prix Nobel de Madame Duflo en 2019), le meilleur chemin épistémologique pour produire de la connaissance fiable, reproductible et bien éprouvée, c’est l’ECR ou mieux encore les méta analyses reprenant des ECR sur un sujet de recherche donné.
Mon projet d’HDR est, depuis 2017, sur cette thématique qui dérange les collègues EC en sciences de l’éducation; j’espère avoir une autre écoute qu’à AMU pour soutenir cette HDR enfin prochainement, ailleurs.
V Bonniol MD PhD MCF
>
J’aimeJ’aime
Bonjour M. Ramus,
je tiens déjà vous remercier pour la clarté dont vous faites preuve dans vos exposés de vulgarisation, que ce soit sur votre blog ou dans vos conférences accessibles sur YouTube.
Je ne suis pas sûr que ma question soit directement liée à la génomique, mais pas sûr non plus du contraire, puisqu’elle concerne un sujet dont on a pu entendre parler cette semaine : la politique de quotas que souhaite mettre en œuvre l’actuelle ministre de l’Education Nationale, Mme Borne, pour faire en sorte que davantage de filles « choisissent » (peut-on encore utiliser ce terme dans ce contexte ?) d’étudier les mathématiques au lycée et en CPGE.
Etant moi-même enseignant dans cette matière, intervenant principalement dans le secondaire, mais faisant également des « colles » dans les filières les plus matheuses de Math Sup (MPSI/MP2I), je ne peux qu’y constater l’évaporation des filles.
Dans ce type de classe, comptant entre 45 et 48 étudiants, on trouve en général moins de 10 filles (par exemple, seulement 4 dans une classe où je colle cette année). C’est à peine plus que ce qu’on comptait lorsque j’étais moi-même étudiant en prépa scientifique il y a plus de 30 ans. D’ailleurs, il me semble que la situation est similaire dans les cursus d’informatique, voire plus marquée.
Ce que j’observe, et qui rejoint le constat général, c’est que des filles ayant obtenu d’excellents résultats au collège, en ont généralement d’un peu moins bons au lycée, choisissent rarement l’option Maths expertes en terminale et se détournent des filières de sciences « dures », en particulier des plus matheuses, dans le post-bac. Au contraire, parmi mes anciens très bons élèves garçons, nombreux sont ceux qui se sont dirigés vers des écoles d’ingénieurs, poussant parfois jusqu’au doctorat.
Lorsque j’interroge mes anciennes élèves, qui ont été pendant des années en tête de classe en maths, elles me disent trouver que cela devient trop dur ou trop abstrait, ou encore que cela ne correspond pas à leur goût, et qu’elles sont plus intéressées par d’autres matières, plutôt la biologie, plus rarement la physique-chimie, pour celles qui ne cessent tout simplement pas d’étudier les sciences.
Pour ce que j’en sais, ce constat est également fait dans la plupart des autres pays. Il existe cependant quelques exceptions connues, comme l’Iran, où les filles sont de toute façon globalement plus nombreuses que les garçons à suivre des études supérieures. Je sais aussi que des politiques volontaristes menées dans certains pays n’ont pas produit les effets escomptés, modifiant très peu le comportement des filles quant à leur orientation.
On nous parle actuellement, pour expliquer ce phénomène, de stéréotypes de genre, ce que je trouve un peu court. Par exemple, nul n’ignore que la profession d’enseignant s’est fortement féminisée, au point que même en mathématiques on trouve une nette majorité de professeures (ce qui n’est pas vrai dans le supérieur). Ainsi, dans l’enseignement secondaire, cette matière ne peut plus, comme ce fut le cas dans le passé, être identifiée par les élèves comme masculine.
J’en viens donc à ma question. Ne pourrait-il pas exister une certaine forme de déterminisme biologique pouvant (au moins partiellement) expliquer qu’un peu partout sur le globe, les filles montrent moins d’appétence pour les mathématiques lorsqu’elles grandissent ? Cela ne me semble pas être une hypothèse saugrenue, puisque si je ne m’abuse, les tests de QI montrent de façon assez universelle certaines différences entre les aptitudes des garçons et des filles.
J’imagine qu’il doit être particulièrement complexe de démêler les causes d’un tel comportement, mais sauriez-vous néanmoins s’il existe sur la question des études intéressantes ?
En vous remerciant par avance pour votre réponse.
H. Clavier
J’aimeJ’aime
Il y a potentiellement plusieurs explications non exclusives à la désaffection des filles pour les orientations STEM:
– différences de préférences intrinsèques entre garçons et filles.
– différences de performance en maths (sans préjuger de leur origine).
– différences de performance dans les matières littéraires (à l’avantage des filles, ce qui fait qu’elles ont un avantage comparatif à aller dans les filières littéraires, même à niveau de maths égal).
– socialisation de genre, stéréotypes de genre, modèles masculins et féminins, et différents biais et freins.
Il me semble qu’il y a des données à l’appui des 4 catégories de facteurs.
Il y a maintenant une conférence en ligne dans laquelle je m’efforce de discuter ces différents facteurs (mais pas tant pour expliquer l’orientation): https://youtu.be/VJlKyljENX4?feature=shared
J’aimeJ’aime
Bonjour,
J’ai regardé beaucoup de vos interventions disponibles en ligne et je les ai trouvé stimulantes et agréables à suivre. J’aimerais avoir votre réponse à deux critiques s’il vous plaît.
1. Ma première critique est la suivante : vous vulgariser beaucoup l’héritabilité, en sachant que celle-ci est souvent mal comprise et interprétée comme signifiant « la part d’un phénotype qui découle de causes génétiques plutôt qu’environnementales ». Il semble judicieux d’être très clair pour éviter cette confusion, et plus encore de ne pas l’entretenir. Or, vous semblez parfois pas assez soucieux d’éviter la confusion et semblez même l’entretenir quand, après avoir parlé d’héritabilité vous parlez de part du phénotype dû au génotype ou d’importance relative des facteurs génétiques et environnementaux de nos caractéristiques, comme ici : https://youtu.be/bw3F9ZNSMmo?si=goLbrZbgPZeLbYll2.
2. Ma deuxième critique porte sur le fait même de vulgariser l’héritabilité plutot que la norme de réaction et de parler de prédispositons plutôt que de réaction. Elle part de celle émise pas un neuroscientifique sur Bluesky :
« Simplifier la biologie et vulgariser l’héritabilité plutôt que la norme de réaction, parler de gènes favorables et de prédisposition à réussir plutôt que de besoins, est un impensé eugéniste et réactionnaire: implicitement, cela postule un environnement fixe pour lequel il y aurait de bons gènes.Un discours fréquent consiste à parler d’héritabilité plutôt que de normes de réaction, puis une fois attaqué à dire qu’on a rien contre changer l’environnement : c’est une contradiction logique (l’héritabilité n’étant définie qu’à environnement fixe) et les gens qui tiennent ces discours le savent ».
Les différences de réussite ne peuvent pas être simplement attribuées à des différences de « prédispositions génétiques », même si l’égalité réelle des chances sociale était réalisée (ressources économiques et culturelles égales, absence de steréotypes, etc.) :
La societé actuelle défavoriserait tout de même certains génotypes et en avantagerait d’autres dans le développement des traits attendus ou non attendus. Tout génotype pourrait exprimer davantage les traits attendus et moins les traits non attendus (ex : agressivité) dans au moins une autre société envisageable (ex : avec une autre organisation scolaire, une autre pédagogie et d’autres exercices). Cela s’explique par le fait que les génomes sont des potentiels conditionnels : chaque génotype possède une courbe spécifique reliant des environnements possibles aux différents niveaux d’expression d’un trait donné (norme de réaction). Un environnement qui traite de manière similaire les individus n’est pas neutre : il avantage certaines génotypes et en désavantage d’autres relativement à d’autres environnements envisageables (quelques uns ou la plupart). Pour illustrer cela, on peut prendre l’exemple d’une tomate A qui produit plus de fruits qu’une tomate B dans un sol acide alors que c’est l’inverse dans un sol alcalin.
Qu’en pensez vous ? Merci d’avance pour vos réponses.
J’aimeJ’aime
Sur le premier point, j’essaie de toujours être clair sur le fait que l’héritabilité est une proportion de variance phénotypique expliquée par la variance génétique. Et non, ce n’est pas équivalent à une proportion du phénotype expliquée par la génétique. Mais comme c’est un peu technique et lourd à manier, il est possible qu’à l’oral je fasse parfois un raccourci simplificateur. Cela dit, vous citez une vidéo d’1h30 plutôt qu’un passage précis, donc la vérification attendra une citation plus précise.
J’aimeJ’aime
J’ai déjà eu l’occasion de lire le 2ème point dans les posts de Jérémie Naudé, mais il m’a toujours laissé perplexe. Pour moi, il n’a aucun sens, ni d’un point de vue théorique, ni d’un point de vue empirique. Et je passe sur l’amalgame absurde (et insultant) entre un concept scientifique et une position politique (qui n’est évidemment pas la mienne, est-il nécessaire de le préciser!).
D’un point de vue théorique: une norme de réaction, c’est la description des effets d’un facteur génétique à travers l’ensemble des environnements. Parfois ces effets varient, on parle alors d’interaction gène-environnement (GxE), parfois pas. Mais qu’il y ait une telle interaction ou pas, cela n’est en aucun cas contradictoire avec un effet principal génétique (=héritabilité). Il est faux que l’héritabilité ne soit définie qu’à environnement fixe. Elle est généralement définie pour l’environnement moyen (à travers l’ensemble des environnements auxquels sont exposés les individus de la population étudiée). C’est le cas à la fois quand on néglige les interactions gène-environnement, mais aussi quand on les quantifie.
Pour le formuler sous forme de modèle statistique élémentaire, on décompose la variance phénotypique (P) en variance expliquée par les gènes (G), par l’environnement (E), par leur interaction (GxE) et par leur covariance (COVGE):
P=G+E+GxE+2COVGE
Le fait que le terme GxE soit non nul n’implique pas que le terme G soit nul ou ininterprétable. Le terme G quantifie l’effet génétique sous l’environnement moyen, et le terme GxE quantifie les variations autour de cette moyenne.
Notez que dans une interaction gène-environnement, les facteurs G et E jouent des rôles symétriques. Par conséquent, si l’on prenait l’argument de Jérémie au sérieux, il devrait le faire à l’identique pour l’environnement. Il devrait dire: « vulgariser l’environnement plutôt que la norme de réaction, parler d’environnements favorables, cela postule un génotype fixe pour lequel il y aurait un bon environnement. (…) Les effets environnementaux ne sont définis qu’à génotype fixe. » Pourtant, je ne l’ai pas vu attaquer des sociologues (ou des spécialistes d’autres facteurs environnementaux) sur ce point.
Je fais l’hypothèse qu’une fois que c’est formulé sous cette forme miroir, ça saute mieux aux yeux que cet argument n’a pas de sens.
Dans le modèle statistique, de la même manière que le terme G quantifie l’effet génétique sous l’environnement moyen, le terme E quantifie l’effet du facteur environnemental pour le génotype moyen.
J’aimeJ’aime
Sur le plan empirique: J’ai l’impression que Jérémie raisonne comme si les interactions gènes-environnement étaient ubiquitaires et de taille importante, de sorte que l’effet principal génétique serait toujours négligeable par rapport aux interactions. Mais une interaction gène-environnement, c’est une hypothèse, et une hypothèse, ça se teste.

Je suis bien au courant qu’à travers toutes les espèces, les gènes et les environnements, on connait des cas spectaculaires, par exemple cette norme de réaction d’Achillea souvent utilisée en cours pour illustrer le concept (moi aussi je l’ai utilisée dans mes enseignements!):
Mais force est de constater que chez l’humain, pour les phénotypes cognitifs qui nous intéressent, des interactions gènes-environnement, on en cherche beaucoup, mais on en trouve peu! (c’est mon constat aussi dans un projet en cours). Que les effets génétiques soient estimés par la méthode des jumeaux ou par des données génomiques, les interactions gène-environnement sont l’exception plutôt que la règle. Et quand on en trouve elles sont généralement de petite taille par rapport aux effets génétiques et environnementaux principaux. Du coup, ne pas les prendre en compte peut conduire à des erreurs dans l’estimation de G et E, mais ces erreurs sont petites et souvent négligeables. Par ailleurs la norme de réaction d’Achillea est très particulière dans le sens où elle illustre des effets génétiques qui semblent s’inverser selon l’environnment (interaction cross-over), avec un effet génétique moyen qui semble nul. Personnellement je n’ai jamais vu de telle interaction dans les recherches chez l’humain. Quand on trouve des GxE, le facteur environnemental module la taille de l’effet génétique (ou l’inverse), mais n’en inverse jamais le signe.
Bref, jusqu’à preuve du contraire, dans toutes les données documentées chez l’humain, les interactions GxE ne semblent pas changer la donne significativement. Ce n’est évidemment pas un argument définitif, mais tout de même, les données empiriques ont leur importance.
On peut dire que c’est de la faute des méthodes limitées utilisées jusqu’à présent qu’on ne trouve pas plus de GxE. Mais si leurs effets étaient aussi importants que l’imagine Jérémie, on devrait les voir comme le nez au milieu de la figure, malgré les limites de nos mesures et de nos modèles.
On peut aussi objecter qu’on trouve peu de GxE parce que les études portent sur des populations soumises à des environnements assez homogènes, pas représentatifs de tous les environnements. Typiquement elles portent sur des populations européennes, avec un biais de recrutement en faveur des SES élevés. Ça c’est une objection tout à fait recevable. Cela dit, nos populations d’étude ont tout de même tout l’éventail des SES, et en général on ne trouve pas d’interaction avec le SES. Là où l’objection a des chances d’être correcte, c’est pour des environnements extrêmement différents (et beaucoup plus variables), dans lesquels (par exemple) une proportion importante des enfants sont malnutris, exposés à de nombreuses maladies infectieuses, et insuffisamment scolarisés. Dans de telles conditions, on s’attend bien sûr à ce que les facteurs environnementaux prennent largement le pas sur les facteurs génétiques, et donc que s’observent des interactions gènes-environnement plus substantielles. Cela serait extrêmement intéressant à observer et cela complèterait notre compréhension des effets génétiques et environnementaux. Cela dit, ça n’enlève rien à l’intérêt d’étudier ces facteurs dans les populations auxquelles nous appartenons, et dans l’espace des environnements auxquels nos enfants sont exposés.
J’aimeJ’aime
Merci beaucoup pour votre réponse détaillée !
Concernant le point 2, j’ai l’impression qu’il y a confusion entre fluctuations d’environnements (entre individus, par exemple de milieux sociaux différents) et changement d’environnement moyen (de société, par exemple si l’organisation scolaire était différente).
J’aimeJ’aime
Il y a clairement 2 sources de variabilité des environnements: entre individus d’une même époque (on pourrait appeler ça des variations spatiales, ou synchroniques), et entre époques (variations temporelles, ou diachroniques). Quand on fait une étude sur une population, on étudie forcément l’effet des variations spatiales de l’environnement, l’espace des environnements observés à l’instant t. Si l’on s’intéresse aux environnements passés, on a quelques idées de ce à quoi ils ressemblaient, et on peut potentiellement estimer leurs effets s’il existe quelque part des environnements actuels similaires. Et puis on peut aussi se demander comment notre génome interagirait avec des environnements futurs qui n’existent pas encore, et là bien sûr c’est l’inconnu!
Mais est-ce que ça affecte l’un de mes arguments?
J’aimeJ’aime