Beaucoup d’enseignants se posent la question légitime de savoir quelle méthode pédagogique est la plus efficace pour atteindre un but donné. Par exemple, parmi toutes les méthodes d’enseignement de la lecture, y en a-t-il certaines qui, mieux (ou plus rapidement) que les autres, permettent aux élèves de reconnaître les mots de manière précise, rapide et fluide, de manière à améliorer leur compréhension et leur plaisir en lecture ? La seule manière de le savoir est d’expérimenter différentes méthodes.
Bien souvent, des enseignants (ou des chercheurs en éducation) essayent une méthode sur des élèves, et se font un avis sur l’efficacité de la méthode en se basant sur les effets observés sur les élèves. Cette démarche est tout à fait naturelle. Elle est le point de départ de toutes les recherches en éducation. Néanmoins, elle ne fournit qu’un niveau de preuve limité. Cette affirmation d’un niveau de preuve limité n’est pas toujours bien perçue ni bien comprise. Il est donc important de la justifier. Cet article[1] va expliquer précisément pourquoi ce niveau de preuve est considéré comme limité.
A l’inverse, de nombreux chercheurs en éducation argumentent que la meilleure méthode pour déterminer l’efficacité d’une pratique pédagogique est l’essai randomisé contrôlé. A nouveau, cette affirmation n’est pas toujours bien perçue, elle est même souvent contestée. Il est donc important de la justifier, ce que va également faire cet article.
Notre argument est que les deux points ci-dessus sont étroitement reliés : c’est pour pallier les limites des observations informelles des effets des pratiques sur les élèves que les différents ingrédients méthodologiques de l’essai randomisé contrôlé ont été assemblés.
« On voit bien que ça marche »
Pour bien comprendre les limites de l’observation informelle, il est utile de faire un détour par l’histoire de la médecine. Rappelons-nous la saignée, cette pratique consistant à vider le patient d’une partie de son sang, utilisée depuis la Grèce antique pour traiter une très grande variété de maux. Bien évidemment, la saignée n’a jamais rien soigné[2] : elle avait pour effet objectif de détériorer l’état des patients, parfois jusqu’à la mort[3]. Pourtant, cette pratique, adoptée par la médecine occidentale, n’a été sérieusement remise en cause qu’au début du 19ème siècle. Les médecins l’ont pratiquée, chacun sur des centaines de patients, en ont observé les effets sur leurs patients, et « ils ont bien vu que ça marchait ». Malgré l’effet objectivement négatif de cette pratique sur la santé des patients, ils sont restés convaincus qu’elle avait un effet positif. Tellement convaincus qu’ils ont transmis cette pratique à la génération suivante, et ainsi de suite pendant 2000 ans.
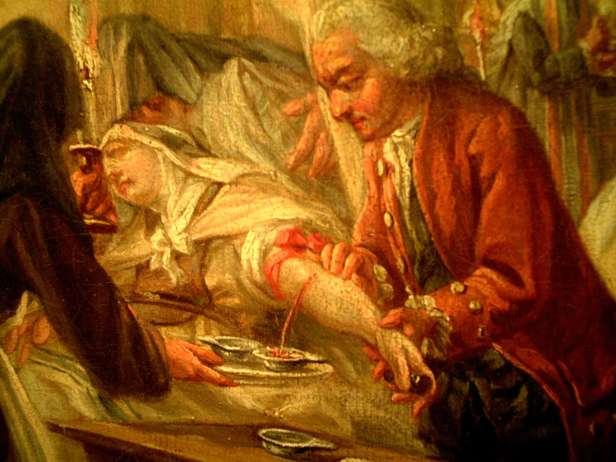
Comment un tel aveuglement est-il possible ? De toute évidence, la simple observation des patients par les médecins ne leur suffit pas à avoir une évaluation objective de l’évolution de leur état de santé.
Vous pensez peut-être que les médecins d’antan avaient une bien piètre formation, et que les médecins du 21ème siècle, forts de 10 années de formation scientifique pointue, ne pourraient jamais être victimes d’un tel aveuglement. Et pourtant, on en voit encore des exemples tous les jours. Par exemple, au 21ème siècle, de nombreux médecins donnent encore à leurs patients des remèdes homéopathiques (ou pratiquent bien d’autres pseudo-médecines), et ont l’impression que ça fait du bien à leurs patients, alors même qu’ils n’ont aucune efficacité objective[4]. En 2020, au cours de la pandémie de COVID-19, on a vu des professeurs de médecine réputés être parmi les meilleurs médecins et chercheurs de leur spécialité, tester tel médicament sur leurs patients, et « ils ont bien vu que ça marchait ». Pourtant, toutes les évaluations rigoureuses conduites en France et ailleurs dans le monde ont montré que ça ne marchait pas[5]. Tels les médecins d’antan pratiquant la saignée, ces médecins de 2020 se sont leurrés en évaluant l’effet d’un traitement sur leurs patients avec une méthodologie à faible niveau de preuve.
De ce point de vue, les enseignants ne sont pas supérieurs aux médecins. Pour exactement les mêmes raisons, lorsqu’ils observent les effets de leurs pratiques pédagogiques sur leurs élèves, et « qu’ils voient bien que ça marche », ils courent un grand risque de se leurrer.
Biais cognitifs et limites de l’observation
Mais pour quelles raisons ? Quel est le problème fondamental de ce genre de méthodes observationnelles ? Il y a en fait de nombreux problèmes, qui découlent principalement du fait que le cerveau humain n’a pas été sélectionné pour déterminer de manière infaillible des liens de cause à effet. Au contraire, nos capacités d’observation et de raisonnement sont limitées. Nous détectons facilement des corrélations, et nous en déduisons souvent des liens de cause à effet, mais le plus souvent nous nous trompons. Tous les êtres humains sont concernés, médecins et enseignants compris.
Premièrement, les observations informelles sont biaisées par les attentes des médecins, de telle sorte que lorsqu’ils sont convaincus de l’efficacité d’un traitement, ils ont tendance à en surestimer les bénéfices observés et à en ignorer les effets délétères. Deuxièmement, quand bien même les médecins se donnent les moyens d’évaluer objectivement l’état de leurs patients, ils n’ont aucune possibilité de déterminer si l’évolution de leur état est due au traitement prescrit ou à d’autres facteurs. En effet, dans la plupart des maladies, l’état des patients s’améliore spontanément avec le temps, sans que cela ait quoi que ce soit à voir avec le traitement.

De même, les observations des progrès des élèves par les enseignants (et même par les chercheurs au fond de la classe) sont biaisées par leurs attentes et leurs croyances. Quand bien même ils évaluent objectivement les progrès des élèves, ils sont dans l’incapacité de déterminer si leur intervention est bien la cause de ces progrès. De fait, au cours de toute intervention pédagogique, le temps passe, l’enfant accumule des expériences, se développe, et en se développant ses capacités cognitives augmentent et ses apprentissages progressent. La conclusion, c’est que s’ils ne s’appuient que sur leurs propres observations informelles de leurs patients ou de leurs élèves, les médecins et les enseignants courent un grand risque de se leurrer sur l’effet de leurs traitements et de leurs pratiques pédagogiques.
Les médecins, les enseignants, comme tous les êtres humains, sont soumis à des biais cognitifs bien connus, qui altèrent leur capacité à évaluer leurs propres pratiques : observations subjectives influencées par les attentes, estimation incorrecte des probabilités, biais de confirmation, mémoire sélective, non prise en compte de l’évolution spontanée, etc. Il y a également des problèmes plus épineux, comme l’impossibilité de savoir ce qui se serait passé si l’on avait procédé autrement. C’est précisément pour cette raison que l’on a mis au point des protocoles permettant d’évaluer objectivement l’effet des traitements en déjouant les multiples sources de leurres. C’est cette approche qui a pris le nom de médecine fondée sur des preuves, qui est aujourd’hui le standard incontournable de toute la médecine. L’éducation fondée sur des preuves est l’application des mêmes principes à l’éducation, pour les mêmes raisons.
Le point épistémologique plus général qu’illustre les exemples de la saignée, de l’homéopathie ou des traitements pour la COVID-19 est qu’il ne suffit pas, pour prouver une hypothèse sur l’efficacité d’un traitement ou d’une méthode, de trouver des observations qui semblent compatibles avec elle (« les élèves ont progressé »). Encore faut-il parvenir à montrer que des hypothèses alternatives (« les élèves ont progressé pour d’autres raisons que ma super méthode ») n’expliquent pas aussi bien ou mieux les observations. Autrement dit, il ne faut pas juste chercher à recueillir des données qui sont compatibles avec l’hypothèse. On peut toujours en trouver, pour tous les traitements et toutes les méthodes, puisqu’avec le temps les patients et les élèves progressent en moyenne. Il faut imaginer d’autres hypothèses, expliciter les prédictions respectives des différentes hypothèses en concurrence, et collecter des données qui permettent de tester ces prédictions là où elles diffèrent, et qui par conséquent permettent de départager les différentes hypothèses. C’est l’essence même de la démarche scientifique.
Prendre en compte les hypothèses alternatives
Explicitons cette démarche avec un cas d’école. Imaginons un enseignant qui invente une nouvelle pratique pédagogique (Méthode A) qui vise à améliorer une certaine Compétence cible ou une autre caractéristique bien définie. L’enseignant l’essaie sur ses élèves, constate que ses élèves semblent bien progresser, et en déduit donc que cette méthode marche. Comme les médecins qui pratiquaient la saignée et qui voyaient bien que ça soignait, il court un grand risque de se leurrer. Reformulons cette situation de manière scientifique, c’est-à-dire sous forme d’hypothèse, sans préjuger du résultat.
· Hypothèse 1 : la méthode A a causé les progrès des élèves. Cette hypothèse prédit qu’à la suite de la Méthode A, les élèves auront progressé. Mais nous allons voir que cette prédiction est insuffisante.
En effet, si l’on veut s’assurer que cette Hypothèse 1 est correcte, alors il faut parvenir à rejeter plusieurs hypothèses alternatives, qui pourraient expliquer les mêmes observations.
- Hypothèse 2 : Les élèves n’ont en fait pas progressé (ou pas autant que l’enseignant ne le croit).
En effet, si l’enseignant n’a pas mesuré objectivement les progrès des élèves dans la Compétence cible, il peut parfaitement se leurrer quant à leurs progrès (à cause des mêmes biais cognitifs qui faisaient que les médecins qui pratiquaient la saignée croyaient que l’état de leurs patients s’améliorait). Cette hypothèse prédit que si on mesure objectivement les progrès des élèves (par des tests), on constatera qu’ils n’ont pas progressé. - Hypothèse 3 : Les progrès des élèves sont sans lien causal avec la méthode A.
Par exemple, les progrès des élèves pourraient juste correspondre à leur développement cognitif spontané pendant la période d’observation, ou à des apprentissages faits en dehors de la classe indépendamment de la Méthode A. Cette hypothèse prédit que si l’on refait l’expérience sur une même durée avec un autre groupe d’élèves sans la Méthode A, ils progresseront autant qu’avec la Méthode A. - Hypothèse 4 (dans le cas où l’on a comparé deux groupes d’élèves A et B): Les élèves du groupe A ont progressé plus que le groupe B (ou sont meilleurs à la fin), simplement parce qu’ils étaient différents au départ.
Peut-être étaient-ils déjà meilleurs dans la Compétence cible, ou avaient-ils plus de marge de progression, ou de capacité à progresser. - Hypothèse 5 : Les progrès des élèves sont dus au fait qu’ils faisaient l’objet d’une expérience, plutôt qu’à la Méthode A.
Par exemple, le seul fait que l’enseignant emploie une méthode pédagogique nouvelle, inhabituelle, rompant la routine, est susceptible d’avoir engendré un regain d’attention et des progrès chez les élèves. Il se pourrait aussi que l’enseignant, plein d’enthousiasme pour la Méthode A, ait communiqué cet enthousiasme aux élèves, engendrant ainsi des progrès. Dans un cas comme dans l’autre, ces progrès peuvent être intéressants, mais ils ne sont pas dus à la Méthode A en tant que telle. Si l’on veut évaluer l’efficacité de la Méthode A, il faut s’assurer que les progrès ne sont pas seulement dus à un tel effet, parfois appelé effet Hawthorne, et similaire à l’effet placebo en médecine. Pour cela, il faut arriver à rejeter les prédictions de l’Hypothèse 5. Ces prédictions sont que, si l’on refait l’expérience avec un autre groupe d’élèves et une autre méthode nouvelle, inhabituelle, pour laquelle l’enseignant est enthousiaste, les progrès seront identiques à ceux observés avec la Méthode A.
Ne pas prendre en compte ces hypothèses alternatives, c’est prendre le risque de se leurrer. Toute recherche qui produit des données compatibles avec l’Hypothèse 1 de l’efficacité de la Méthode A, sans prendre le soin de tester ces hypothèses alternatives et de montrer qu’elles ne peuvent pas expliquer aussi bien les données, ne peut en fait rigoureusement pas conclure que l’Hypothèse 1 est confirmée. Cela n’implique pas qu’elle soit inutile : les nouvelles pratiques sont souvent inventées à partir des intuitions et des essais informels des enseignants. Mais ces derniers ne peuvent pas constituer une preuve. Ils doivent être suivies d’une recherche plus rigoureuse pour pouvoir aboutir à un début de preuve.
L’essai randomisé contrôlé
Voyons maintenant comment tester les prédictions de ces hypothèses alternatives et donc départager les différentes hypothèses.
|
Hypothèse alternative |
Méthodologie |
|
Hypothèse 2 : Les progrès ne sont qu’apparents: en réalité, les élèves n’ont pas progressé |
Mesurer objectivement le niveau des élèves dans la Compétence cible avant l’intervention pédagogique, et après. Idéalement, les tests devraient être administrés par une personne différente de l’enseignant ou du chercheur à l’origine de l’hypothèse, et qui ignore à quelle méthode les élèves ont été exposé, afin d’éviter des biais de mesure liés aux attentes et aux croyances de l’observateur. |
|
Hypothèse 3 : Les progrès des élèves sont sans lien causal avec la méthode A. |
Comparer un groupe d’élèves (A) qui reçoit la Méthode A, et un groupe témoin (B) qui ne la reçoit pas. Si le groupe A progresse significativement plus que le groupe B (comparaison statistique), alors on peut en conclure que la Méthode A est plus efficace que ce à quoi ont été exposés les élèves du groupe B. |
|
Hypothèse 4 : Les élèves des deux groupes étaient différents au début de l’expérimentation, c’est pour cela qu’ils sont différents à la fin. |
S’assurer que les groupes d’élèves qui sont comparés ne diffèrent pas avant le début de l’expérimentation, ni dans la Compétence cible, ni dans tout autre caractéristique (sociale, cognitive) qui pourrait influencer la capacité à progresser dans cette compétence. Il est donc utile de mesurer ces Compétences et caractéristiques avant le début de l’expérience, et de les comparer entre les deux groupes. Néanmoins, comme il est en pratique impossible de mesurer toutes les caractéristiques pouvant potentiellement avoir un effet, la meilleure méthode est :
Ces deux conditions permettent d’assurer que les deux groupes auront très peu de risque de différer sur quelque caractéristique que ce soit en moyenne. Si les groupes comparés ont des enseignants différents, alors les remarques ci-dessus devraient aussi s’appliquer aux enseignants. |
|
Hypothèse 5 : Les progrès des élèves sont dus au fait qu’ils faisaient l’objet d’une expérience, plutôt qu’à la Méthode A. |
S’assurer que le groupe B n’est pas juste soumis à l’enseignement habituel sans changement. Il doit lui aussi être soumis à une intervention, administrée par un enseignant enthousiaste, mais il doit s’agir d’une intervention qui n’est pas censée améliorer la compétence cible. Par exemple : si la Méthode A concerne l’enseignement de la lecture, la méthode B peut :
|
L’ensemble de ces ingrédients constitue la méthodologie de ce qu’on appelle l’essai randomisé[6] contrôlé.
Si l’on constate que le Groupe A progresse significativement plus que le Groupe B, et que l’on a bien adopté toutes les méthodes listées dans le tableau, alors on pourra conclure que les Hypothèses alternatives 2, 3, 4 et 5 sont peu plausibles, et par conséquent que l’hypothèse la plus plausible pour expliquer les données est l’Hypothèse 1 : non seulement les élèves progressent avec la Méthode A, mais il semble bien qu’il y ait un lien causal entre l’usage de la Méthode et les progrès des élèves.

Cette liste de méthodes peut sembler très longue, très lourde et très coûteuse à mettre en œuvre. C’est parfaitement vrai. L’essai randomisé contrôlé n’est pas à la portée d’un enseignant qui souhaite tester une nouvelle idée, ni même à la portée d’un établissement. Un appui méthodologique de la part de chercheurs est nécessaire, ainsi que des moyens et une organisation particulière permettant de mettre en place l’intervention témoin et le tirage aléatoire. Faire un essai randomisé contrôlé est compliqué, même pour les chercheurs. Si on pouvait atteindre le même niveau de preuve plus simplement, on le ferait. Mais on ne peut pas.
En effet, chaque ingrédient méthodologique mentionné ci-dessus est justifié soit par la nécessité de contrôler des biais dont la réalité est démontrée, soit par la nécessité de tester rigoureusement l’hypothèse considérée contre des hypothèses alternatives (dont il est également démontré qu’elles sont justes dans certains cas). Dès que l’on omet l’un de ces ingrédients méthodologiques, on échoue à rejeter l’une des hypothèses alternatives, et alors on ne peut pas rigoureusement conclure que l’Hypothèse 1 est correcte. On a peut-être obtenu des résultats compatibles avec l’Hypothèse 1, mais on ne l’a pas prouvée.
Pour revenir aux deux questions que nous avons soulevées en introduction :
- Pourquoi l’observation informelle par l’enseignant (ou un chercheur) des effets de sa pratique sur les progrès de ses élèves est-elle une méthode qui a un niveau de preuve limité ? Parce que l’hypothèse selon laquelle les progrès des élèves ont été causés par la pratique de l’enseignant n’est qu’une hypothèse parmi d’autres. Pour prouver que cette hypothèse est juste, il faut arriver à montrer que les hypothèses alternatives qui pourraient expliquer les mêmes observations sont fausses.
- Pourquoi l’essai randomisé contrôlé est-il considéré comme la méthode d’expérimentation ayant le plus haut niveau de preuve ? Parce qu’il incorpore dans sa méthodologie tous les ingrédients permettant de tester et éventuellement de rejeter les hypothèses alternatives.
La hiérarchie des niveaux de preuve
L’essai randomisé contrôlé constitue donc le niveau de preuve le plus élevé. C’est ce vers quoi l’on doit tendre. Mais bien entendu, ce n’est pas un standard que l’on peut exiger des enseignants, ni même de tous les chercheurs. Il est de plus matériellement impossible de tester toutes les idées des enseignants de cette manière. Il est donc normal qu’il existe tout un continuum de méthodes, de plus en plus sophistiquées, incorporant de plus en plus d’ingrédients méthodologiques permettant de rejeter des hypothèses alternatives, et participant progressivement à la construction d’une preuve d’efficacité:
- Il est tout à fait normal qu’un enseignant ayant une nouvelle idée souhaite la tester avec ses élèves. Il doit juste être conscient que ses observations informelles ne fourniront pas de preuve. Elles alimenteront simplement son intuition sur l’efficacité de la méthode.[7]
- Si les observations informelles d’un enseignant suggèrent qu’il est sur une bonne piste, alors la prochaine étape serait de tenter une véritable expérimentation. Pas un véritable essai randomisé contrôlé à grande échelle, mais une expérience à petite échelle (quelques classes), avec a minima des mesures objectives des compétences cibles avant et après intervention, et autant que possible un groupe contrôle. Le niveau de preuve obtenu sera plus élevé que pour les observations informelles, mais certaines hypothèses alternatives ne seront pas rejetées, et donc on ne pourra pas conclure définitivement.
- Une fois qu’une ou plusieurs expériences ont fourni suffisamment d’éléments à l’appui d’une méthode, alors il peut être légitime de chercher à obtenir le niveau de preuve le plus élevé, en menant un essai randomisé contrôlé. A ce stade, la collaboration entre enseignants et chercheurs est indispensable, de même qu’une échelle dépassant celle d’un seul établissement.
- Une fois qu’un ou plusieurs essais randomisés contrôlés ont été menés et se sont avérés concluants, une dernière étape peut être utile : le passage à grande échelle. En effet, déployer une nouvelle pratique pédagogique à grande échelle, auprès de nombreux enseignants qui ne sont pas tous nécessairement volontaires et motivés (contrairement à la plupart des expériences à petite échelle), comporte de nombreux défis supplémentaires et peut échouer pour bien des raisons. Néanmoins, ce n’est qu’à l’issue d’une telle étude de passage à l’échelle que l’on serait véritablement fondé à engager une réforme pédagogique au niveau national.
Il ne s’agit donc pas de dire qu’il n’y a point de salut en dehors de l’essai randomisé contrôlé, et que ce standard le plus élevé doit s’imposer à tous en toutes circonstances. Il y a de la place pour une diversité de méthodes. Néanmoins, il serait sain que chacun comprenne les limites des différentes méthodes, et lors de la discussion de résultats d’expérimentations, soit capable de situer chaque résultat dans la hiérarchie des niveaux de preuves. Les débats en éducation y gagneraient en qualité. Les recherches en éducation y gagneraient aussi. En situant chaque hypothèse pédagogique dans la hiérarchie, il apparaitrait mieux quelles étapes suivantes sont nécessaires afin de faire progresser le niveau de preuve, et donc d’apporter une réponse plus fiable aux questions qui sont posées.

Au-delà de l’essai randomisé contrôlé
Une fois qu’une hypothèse a été testée par essai randomisé contrôlé, la messe est-elle définitivement dite ? Non, bien sûr. Un essai randomisé contrôlé n’est qu’une étude, et une étude a toujours des limites : l’effectif peut être limité, les mesures peuvent être de qualité limitée, la méthodologie peut avoir été imparfaitement suivie, les groupes peuvent avoir été différents au départ par hasard malgré le tirage au sort, etc. Il est fort possible qu’un nouvel essai randomisé contrôlé sorte la semaine suivante et affiche le résultat opposé. Cela se voit couramment. Le résultat d’une seule étude, même au plus haut niveau de preuve, n’est donc jamais une conclusion définitive. Ce n’est que par l’accumulation de multiples études que l’on peut déterminer si les résultats montrent une tendance fiable, malgré les inévitables contradictions. Les méta-analyses, qui synthétisent les résultats de multiples études, permettent de déterminer cette tendance de manière fiable, et définissent donc le sommet de la pyramide des preuves.
Un essai randomisé contrôlé n’est qu’une étude, et une étude donne toujours un résultat qui est valable sur la population et dans les conditions dans lesquelles elle a été menée. La généralisation à d’autres populations ou d’autres conditions peut être hasardeuse. Parfois, cette dépendance du résultat au contexte est brandie comme la preuve que ces études sont irrémédiablement biaisées ou inutiles. Ce n’est pas la bonne conclusion. Dans quelle mesure les résultats d’une étude sont généralisables à d’autres populations, d’autres pays, d’autres contextes éducatifs? C’est à nouveau une question scientifique, qui est parfaitement testable. Il suffit pour cela de reproduire de telles études à travers de multiples populations, pays, et contextes. Si les résultats sont invariablement les mêmes, c’est qu’ils étaient bien généralisables. S’ils varient en fonction de la population ou du contexte, alors c’est un résultat intéressant aussi. C’est d’ailleurs l’enjeu de nombreuses recherches en éducation que de comprendre dans quelle mesure certaines pratiques pédagogiques conviennent à tous les élèves, et dans quelle mesure elles conviennent à certains plus qu’à d’autres (et dans ce cas, que peut-on proposer de mieux à ces derniers?).
Par conséquent, le fait que le résultat d’un essai randomisé contrôlé (comme toute étude) soit nécessairement dépendant de la population et du contexte dans lequel il a été effectué ne peut pas être un argument générique contre les essais randomisés contrôlés. Au contraire, c’est une bonne raison pour en conduire plus, dans des populations et des contextes différents. Lorsqu’un certain nombres d’études ont été menées sur une même intervention pédagogique, à travers plusieurs populations ou contextes, les méta-analyses qui en synthétisent les résultats sont capables de déterminer rigoureusement dans quelle mesure les effets dépendent de la population et du contexte, et dans quelle mesure ils sont généraux.
Conclusions
Si l’on veut que la qualité de l’enseignement progresse, il faut que la qualité de la recherche en éducation progresse. Pour cela, il est absolument crucial que tous les enseignants et tous les chercheurs en éducation réalisent les limites des méthodes observationnelles qui « montrent bien que ça marche ». Il est véritablement difficile de prendre conscience qu’on peut être trompé par ses propres observations, qu’on peut avoir l’impression d’observer des progrès qui sont fictifs, ou qui ne sont pas dus à la pratique pédagogique expérimentée. C’est un grand exercice d’humilité pour tous, enseignants, chercheurs, technocrates et décideurs dans le domaine de l’éducation, qui ont tous des opinions sur de nombreux sujets, basées sur leurs observations.
Ce que nous avons montré ici, c’est finalement qu’obtenir des réponses fiables sur « ce qui marche en éducation » est difficile, extrêmement difficile. Beaucoup plus difficile que ne l’imaginent la plupart des gens, des enseignants, des décideurs et même des chercheurs en éducation. Une telle difficulté, qui devrait conduire à une très grande humilité, contraste de manière saisissante avec la facilité avec laquelle chacun s’autorise à donner son opinion sur ce qui marche.
Dans un débat rationnel sur les questions d’éducation, toute personne qui affirme que « telle pratique pédagogique marche » devrait être capable :
- De donner les sources sur lesquelles elle s’appuie : Quelle(s) étude(s) scientifique(s) ? Publiée(s) où ? A défaut, quel rapport ? Quelles observations ? Où peut-on en consulter les résultats pour se faire son propre avis ?
- De préciser la méthodologie qui a été utilisée.
- D’expliciter quelles hypothèses alternatives ont été rejetées, et comment.
- De situer le résultat dans la hiérarchie des niveaux de preuves.
Je rêve d’un monde où toutes les personnes qui assènent leur opinion sur des pratiques pédagogiques respecteraient ces quelques principes. A défaut, dans la mesure où il n’est pas question de restreindre la liberté d’expression, ces critères fournissent une grille d’évaluation que chacun peut appliquer aux affirmations qui sont émises quotidiennement dans le domaine de l’éducation, ou encore une liste de questions que l’on devrait systématiquement poser à tous ceux qui font de telles affirmations.
[1] Des extraits de cet article sont également inclus dans le rapport « La recherche translationnelle en éducation : Pourquoi et comment ? » publié en 2020 par le Conseil scientifique de l’éducation nationale.
[2] A part quelques maladies très particulières, comme l’hémochromatose.
[3] Lire par exemple le récit de la mort de George Washington dans l’article de Singh & Ernst (2011).
[4] Sur l’homéopathie, voir par exemple l’argumentaire complet du collectif Fakemed. Et plus généralement: le site du collectif Fakemed, et le manifeste mondial contre les pseudosciences en santé.
[5] A propos de l’efficacité des traitements pour la COVID-19, voir la synthèse de la Société française de pharmacologie et de thérapeutique.
[6] L’anglicisme « randomisé » fait référence au tirage aléatoire des élèves dans les deux groupes.
[7] Même à ce niveau, il y a moyen de faire mieux que des observations totalement informelles. Par exemple, le Collectif Profs-Chercheurs fournit un cadre qui permet aux enseignants de préciser leurs questions et de mener leurs observations de manière plus rigoureuse, de manière à renforcer ce premier niveau d’évaluation et à mieux identifier les pratiques prometteuses qui mériteraient d’être évaluées de manière expérimentale.

La méta analyse n’est fiable que pour autant qu’elle agrège des études fiables
Le problème de la validité externe des résultats me paraît plus devoir être recherché dans la multiplication des études fiables dans des environnements différents
J’aimeJ’aime
Bonjour M. Ramus, et merci pour ce post.
Vous soulevez le fait que l’enthousiasme d’un professeur va influer sur l’apprentissage des élèves. Ne pensez vous pas que la formation et les types antérieurs de méthodes maîtrisées par d’un professeur va influer aussi ?
Un professeur qui essaie volontairement (phase 1 2 et 3) une nouvelle méthode le fera généralement dans des paramètres avec lesquels il est confortable. Il est plausible que la méthode soit plus adapté, non pas aux élèves en général, mais à ce professeur et qu’elle augmentent sa propre efficacité. Cette hypothèse ne devraient pas être écartée d’office me semble-t-il.
Inversement, une méthode éprouvée par des études rigoureuses risque d’être déployée de manière rapide et disons « abrupte » (pour être très gentil), au niveau de l’éducation nationale, sans formation, un peu au dernier moment et potentiellement sans prise en compte en amont des habitudes des professeurs.
Cela en soit est un risque d’échec, tout comme changer le geste technique d’un tennisman juste avant un match, ça n’est pas efficace.
La formation reste malheureusement très insuffisante dans l’éducation nationale en tout cas dans les niveaux collèges et lycées.
J’aimeJ’aime
Bonjour Monsieur Ramus
J’étais certain que vous rédigeriez un tel article traçant en filigrane un parallèle entre les rapports confrontant les différents conseils scientifiques et les évaluateurs de méthodes. Prévisible… mais toujours aussi intéressant, clair, rigoureux et complet. J’y apprécie particulièrement ce nouvel éclairage sur la difficulté pour les pédagogues à valider les hypothèses, qu’ils croient parfois conclusions, en trouvant une synergie prospective faisant collaborer praticiens et universitaires, toujours séparés par un vide abyssal.
Je ne puis d’abord m’abstenir d’une longue parenthèse nuançant le pied-de-nez que vous faites aux experts de la covid. Alors que mon sujet, c’est la lecture.
Personne ne pourra (ne devrait) nier la puissance de la randomisation. Pour autant, elle ne sera jamais qu’un élément de sécurité parmi d’autres, tout comme le dispositif de freinage en est un dans une automobile. La validité d’une étude sur certificat par randomisation ou non a été largement galvaudée, dans les derniers mois, sur fond de covid19. Beaucoup se satisfaisant arbitrairement de cette seule estampille pour convenir sans vérification de la probité ou de l’utilité, par son champ d’application, du travail présenté. Ne jurant (jugeant), hâtivement souvent, que par la source (voir The Lancet gate). Celui qui affirme sans preuve n’a pas nécessairement tort, mais on ne peut pas plus croire une personne sur parole, foi de sa notoriété, de son expérience. Pour autant, la randomisation, ne peut se faire tête de gondole ou paravent, c’est une clé de sécurité supérieure toutes choses étant égales ou comparables par ailleurs. Or, vous l’avez remarquablement décrit, les biais sont très nombreux ou difficiles parfois à gommer, et cette ultime clé ne peut effacer à elle seule les errances préalables ou connexes, tant en préparation qu’en interprétation. Je déplore en retrouver encore beaucoup parmi les études agrégées dans l’article en lien de la SFPT sur lequel vous prenez appui et dont on doit normalement attendre le sérieux (bien qu’y figure toujours l’étude de Mehra, comme si certains avaient du mal à renoncer à cette fugace preuve qui les avait tant confortés!). Je vous ferai grâce de l’exégèse des 5 études randomisées étrangement accommodées pour peser en tableau, avec force caractères gras en raccourcis faciles, alors qu’aucune ne pose la même question. De nature fort hétéroclite en réalité et dont on tire des enseignements sur une molécule plus que sur une posologie, autre biais récurrent, avec pour seule certification de la sélection ici, la caution d’un « consensus d’experts »… anonymes, nonobstant. Là encore on voudrait vanter la qualité méthodologique (non en cause) par l’exclusivité de pratiques randomisées alors qu’on s’exonère de statuer sur la qualité de l’hypothèse, ou de se demander si l’on pose la bonne question au bon endroit. Par exemple est mise en exergue l’étude de Mitjà et al. (https://doi.org/10.1093/cid/ciaa1009) , (idem pour Skipper et al, soit 2 sur 5 déjà) clamant l’inefficacité de l’HCQ (seule) en traitement précoce. Dont acte, cette conclusion peut être retenue. Mais on voudrait intuitivement laisser entendre ainsi qu’elle suffirait à contredire les résultats des promoteurs de la substance controversée dans le traitement de la covid. Belle embrouille, il n’en est rien. Car ces derniers constatent également la nette infériorité de l’HCQ sur l’Azithromycine (absente des deux études sus-citées) à ce stade de la maladie pour réduire la charge virale.
Cliquer pour accéder à Hydroxychloroquine_final_DOI_IJAA.pdf
Sans compter la potentialisation de l’une sur l’autre (Fantini) :
https://www.sciencedirect.com/science/article/pii/S0924857920301837?via%3Dihub
Ce qui me trouble toujours, c’est la facilité avec laquelle on peut faire passer une vessie pour une lanterne lorsque le destinataire est fasciné par la provenance, focalisé sur l’abstract ou la conclusion surlignée, et insouciant du détail.
On pourrait également lire l’article suivant : https://blog.gerardmaudrux.lequotidiendumedecin.fr/2020/10/25/chloroquine-le-plus-grand-scandale-sanitaire-francais-du-siecle/
qui offre un tout autre angle de lecture et de toutes autres conclusions, critiquable également pour une sélection orientée et discutable.
Il ne s’agit pas seulement de savoir (on aimerait bien) qui a tort et qui a raison, mais d’observer, décortiquer et critiquer les stratégies dont chacun use pour y parvenir, parfois coûte que coûte.
Ainsi, si la cause semble entendue pour certains, je reste beaucoup plus réservé quant à l’idée de promouvoir ou d’interdire un seul (LE) médicament pour une maladie qui comporte plusieurs stades distincts, plusieurs évolutions antagonistes, plusieurs effets induits, plusieurs cofacteurs,etc. Le parallèle avec la lecture revient ici en résonance car il s’agit également d’un apprentissage multifactoriel, qui se déroule en différents lieux ou différents stades et qu’il serait fort complaisant, au fond, comme on le fait trop souvent de vouloir solutionner par l’imposition d’un joli manuel à l’intention du CP.
La question est en fait plus large. Le problème ne réside pas (que) dans l’objet mais dans l’usage que l’on en fait, et l’exemple médical sera très instructif. Si la recherche était publique et désintéressée, nous ne serions même pas là à en débattre. Sauf que le marché du médicament, car c’est bien un, doit faire avec les ressources et les bénéfices que les entreprises doivent en tirer. Si ce n’est pas un biais… ?
Au grand étonnement de tous, l’hydroxychloroquine a été classée en janvier 2020 substance vénéneuse sur demande du laboratoire qui l’a conçue, après l’avoir exploitée en toute sécurité pendant des décennies. Ce hasard de calendrier fut interprété par certains – il seraient complotistes dit-on, selon le nouvel argument d’autorité – comme un signe de malveillance à l’encontre du mentor marseillais ou de la possibilité de traiter. Qui s’égare ? Tous, pourquoi pas ? Peut-être n’est-ce que coïncidence et non lié à l’épidémie en cours. Le laboratoire commencerait par exemple, depuis 2018, à décrédibiliser sa propre molécule, aujourd’hui génériquable, pour que celle-ci ne profite pas à tous ceux qui n’ont pas payé pour sa mise en service. Gageons que d’ici quelques mois, au moins une molécule de substitution à l’HCQ, dûment étalonnée en étude randomisée, à peine meilleure pour ci ou pour ça, mais plus chère à n’en point douter, apparaîtra dans le paysage avec une couverture en brevet bien plus lucrative à l’avenir pour les actionnaires. Ce n’est qu’une hypothèse, pas une condamnation ni une prédiction, mais c’est une réalité économique de laquelle ne peut s’extraire l’industrie pharmaceutique.
Ne négligez surtout jamais ce point-là dans l’affaire HCQ, y compris pour la manière dont on conduit ou considère les différentes études. Il faut rester prudent dans cette histoire. Si on ne peut exclure que DR ait eu la berlue, penser ou suggérer que les dizaines de scientifiques de haut vol qui gravitent autour soient subitement devenus fous, sourds, aveugles, incompétents et compromis me paraît très irrespectueux.
Les laboratoires Roche et Novartis viennent d’être condamnés pour entente illicite ; où l’on se refusait à faire l’étude confirmant l’efficacité de l’Avastin (anticancéreux) contre la DMLA… pour en vendre un autre, le Lucentis, plus spécifique mais quasi identique et pas plus efficace, 25 fois plus cher. Un laboratoire peut donc tout à fait renoncer à prouver l’efficacité de son médicament pour de sombres raisons mercantiles et même s’entendre avec d’autres pour y parvenir. (D’ailleurs, Sanofi, qui n’a rien financé pour l’HCQ, a conduit avec Regeneron des tests randomisés sur une autre molécule, sarilumab, contre le sars-cov2… Curieux, non ?)
Je ne peux, à l’échelle de ma classe, que présenter des hypothèses, des résultats « encourageants », mais en aucun cas prouver quoi que ce soit. Vous avez raison de calmer les ardeurs de tous ceux qui jubilent et pérorent devant quelque exploit local sans comparatif. Ma formation scientifique, en microbiologie (d’où mon intérêt pour la question médicale), m’interdit de distiller ce genre d’affirmation péremptoire et non étayée. Ce n’est pas qu’une difficulté méthodologique, ou une retenue déontologique, c’est surtout une question de moyens pour obtenir les preuves. Mais pour enseigner face à un CP on ne peut pas toujours attendre des confirmations lointaines. Il faut bien faire un choix opérationnel immédiat sur une stratégie d’apprentissage, il faut aller au front et assumer ses responsabilités. Ce choix serait biaisé s’il n’était fondé que sur des intuitions (il a bien fallu faire avec depuis le début de ma carrière!). Et je me tromperais donc probablement en croyant voir progresser mes élèves selon mes préjugés alors qu’une comparaison avec une autre approche pourrait me démontrer le contraire. Cela je m’en suis accommodé longtemps parce que je reste humble et que j’œuvrais initialement dans des conditions assez standard au CP avec de «sobres aménagements des pratiques». Mais jusqu’à un certain point. Le jour où l’on me montrera une approche pédagogique qui permet de dépasser ce que je fais et constate aujourd’hui en GS, et pas au CP, je changerai illico de destrier. En attendant, pour moi la causalité semble se confirmer année après année. Je ne peux renoncer, le gap est trop énorme, mais le doute demeure.
J’aimeJ’aime
Bonjour Marcel, je ne vous répondrais pas sur la lecture (je n’ai pas lu les études dont vous parlez), mais pour l’HCL oui.
L’étude de Mehra et als publiée sur le Lancet ne pose pas de gros problème : il y a une rapide réponse du milieu scientifique, et après de nouvelle vérification, l’article a rapidement été rétracté (il est toujours visible avec cette mention qui l’invalide). Cet article n’est plus cité comme preuve, le falsificateur est resté dans le silence. https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(20)31180-6/fulltext
En comparaison, M. Raoult écrit dans ses deux études publiées que l’HCL est efficace dans les cas « moyens et sévère » et « tous les cas sauf un », alors que des études randomisée à grande échelle avec une meilleur méthodologie donne un bien meilleur niveau de preuve applicable à la question : l’HCL est elle efficace sur des malades hospitalisés ? Avec une réponse négative.
La première étude de M. Raoult, la seule avec un groupe test, celle qui dit que l’HCL est efficace sur tous les patients sauf un, décrit aussi p10 qu’il y n’y a eu des aggravation que dans son groupe HCL et pas son groupe test (3 réanimation, un mort !), ce qui montre son niveau de rigueur. Cette étude a été retiré à cause de nombreux problèmes (de l’ordre de la falsification aussi), mais les gens (pas les chercheurs) continuent à faire références à cette étude, et on écoute toujours l’auteur qui s’exprime volontier …
Je vous invite à lire la première étude de M. Raoult, toujours disponible sur son site (la mention « retiré » n’y figure pas …), apparemment vous savez critiquer un protocole, vous aurez moyen d’y voir quelques pépites qu’on ne pardonnerait pas à un élève de 1ère année.
Cliquer pour accéder à Hydroxychloroquine_final_DOI_IJAA.pdf
J’aimeJ’aime
Merci,
Je ne veux pas trop polluer l’espace de Franck Ramus par un débat personnel. Je sais parfaitement que les premières études (si on peut accepter ce terme pour un tel type de papier!) sont de piètre qualité ou intérêt… Urgence ou pas urgence, y a-t-il un justificatif à cette communication empressée et vaniteuse? Une fois le reproche fait, on suit l’affaire et on voit qu’elle n’est pas aussi simple qu’il n’y paraissait en avril. Le professeur vient de déposer plainte contre l’ansm me semble-t-il. Je ne suis pas sûr qu’il se lance dans cette aventure sans un minimum de billes. Plusieurs spécialistes (mais je n’ai pas vu leurs propos) partent aussi à l’assaut de la méta-analyse de Fiolet etcoll. Il y a donc toujours de l’activité critique. Tant mieux pour la science. Laissons-là s’exprimer.
J’aimeJ’aime
(désolé pour le doublon)
Comme vous le soulignez, ses premières études sont de piètre qualité, vous notez donc bien qu’il s’est lancé dans l’aventure sans aucune bille pour dire « covid endgame ».
Étant donné qu’il a fait une demande de mise sur le marché de l’HCL sans préciser de dosage, vous pouvez être sûr que sa plainte n’est destiné qu’aux média et à son public, car sa demande ne pouvait être accepter même sur la forme. Il a fait exprès de faire une demande qui allait être refusée : on ne met pas un médicament sur le marché pour une utilisation, on met un dosage particulier d’un médicament. L’HCL n’a pas le même dosage comme anti-paludéun et contre le lupus par exemple.
Si vous comprenez quelque chose à sa manoeuvre, moi pas …
J’aimeJ’aime
Effectivement Marcel, si j’avais réagi plus tôt, j’aurais probablement édité votre message et supprimé toute la partie sur l’HCQ. C’est hors sujet ici, je ne suis pas d’accord pour qu’on profite d’un de mes articles sur la recherche en éducation pour faire de la pub pour le gourou de Marseille, alors que c’est un sujet que je m’abstiens délibérément d’aborder, parce que c’est hors de mon champ d’expertise (même si j’ai moi aussi une opinion sur le sujet!). Je propose donc qu’on arrête là sur ce sujet, et qu’on revienne à l’éducation.
J’aimeJ’aime
Je suis entièrement d’accord pour que vous supprimiez la partie HCQ que j’observe avec distance et neutralité /zéro pub. Vous pouvez même effacer l’ensemble de mon message s’il vous parait outrageant. Je m’excuse de m’y être attardé. Je suis simplement parfois gêné que la « randomisation » soit utilisée comme seul gage de validité quand tant d’autres paramètres constitutifs d’un essai méritent d’être scrutés finement. Le reviewing devrait servir à éviter ça. Mais la crise, toujours en cours, a montré que même ce point d’appui reste friable, parce qu’humain et parfois sujet à pressions, au moins dans certains domaines.
Pour en revenir à l’éducation, je résume mon propos en ce que si ce secteur a bien besoin de construire des champs de certification des « bonnes pratiques », j’ai surtout peur que l’on finisse par terriblement contraindre l’innovation pour finalement tourner en rond. Il est vraiment difficile de véhiculer une expérience qui modifie les habitudes ou remet en questions certains préjugés, voire connaissances. Je l’ai observé et proposant des changements drastiques dans la construction d’une progression que certains jugent par avance inacceptable car trop éloignée des standards acceptés de la majorité. Or s’il faut être d’abord majoritaire pour être ne serait-ce qu’écouté, cela devient impossible d’exister seulement.
J’aimeJ’aime
Il est parfaitement possible (et souhaitable) que des idées nouvelles émergent. Et bien sûr, lorsqu’elles émergent, elles sont toujours minoritaires. Il n’est nullement nécessaire qu’elles soient majoritaires pour qu’on s’y intéresse et qu’on ait envie de les évaluer, pour savoir si ce sont de vraies bonnes idées.
Parmi toutes les idées nouvelles qui émergent, lesquelles méritent d’être soumises à une évaluation? Celles qui ont un minimum de plausibilité, compte tenu des connaissances actuelles. Ou a minima, celles qui peuvent être justifiées par un argumentaire convaincant. Si vous avez inventé une nouvelle progression d’apprentissage de la lecture, vous devez être capable d’expliquer pourquoi vous pensez que cette progression est meilleure que d’autres. Et si vous avez raison, vous devez être capable de m’en convaincre (ou d’en convaincre quelqu’un). Si vous n’arrivez à convaincre personne avec vos arguments, il est bien sûr concevable que vous ayez raison contre tous, que vous soyez un génie incompris. Mais disons que la probabilité est faible.
Après, j’ai bien expliqué ci-dessus qu’on ne peut pas exiger un fort niveau de preuve d’un enseignant qui a une idée nouvelle. C’est pour cela qu’il faut y aller de manière proportionnée: ajuster le niveau d’exigences au niveau d’élaboration de la nouvelle hypothèse, et au coût de la prochaine étape d’évaluation.
J’aimeJ’aime
J’ai déjà proposé mon travail aux journées académiques de la pédagogie (Aix-Marseille), mais j’y ai surtout constaté que les supposés relais étaient d’évidence plus intéressés par les cocktails que par la réflexion didactique… Johannes Ziegler m’avait un peu volé la vedette ce jour-là… avec une excellente conférence, au demeurant. Les canadiens et les tunisiens étaient venus, eux au moins, pour voir de l’innovation. J’ai eu de meilleurs contacts, une immédiate approbation, et surtout une compréhension sans a priori. Comme je n’ai pas eu de retour aux différents contacts dans le « milieu » EN, puis constaté la moue effarouchée des éditeurs sollicités, je publierai sans doute d’une manière moins directe. Pas sous forme de méthode (je peux contourner le format habituel), et plus probablement de démonstration logique. Mais tout cela est compliqué, et long, car j’ai bien entendu d’autres ouvrages à conduire pour animer ma classe, et tant d’autres contraintes extra-professionnelles. Et puis, je continue jour après jour à améliorer et affiner mes idées, n’hésitant jamais à mettre au panier tout ce qui faillit. Si je parviens à aller au bout, je vous en communiquerai l’essentiel. Je l’avais déjà fait, pour un premier jet, en direction du gourou auvergnat (plaisanterie sans mépris)… sans réponse.
J’aimeJ’aime
Sur la randomisation, j’ai bien expliqué qu’il s’agissait d’un ingrédient méthodologique parmi d’autres, qui est le meilleur moyen de rejeter certaines hypothèses alternatives, mais pas toutes. Par conséquent, il n’est pas question de dire que la randomisation est la condition nécessaire et suffisante de la validité d’une recherche.
J’aimeJ’aime
Merci de rappeler que le consensus scientifique (basé maintenant sur des centaines d’essais randomisés contrôlés et des dizaines de méta-analyses) sur l’enseignement de la lecture est que les méthodes phoniques (qui enseignent systématiquement et explicitement toutes les correspondances graphèmes-phonèmes) sont plus efficaces que les méthodes non phoniques. C’est peut-être le résultat avec le plus haut niveau de preuve dans toute la recherche en éducation, et on ne peut que se désoler qu’il puisse encore être contesté ici ou là (même si cela se voit de moins en moins, je vous l’accorde).
Après, vous vous désolez que ce résultat solide au-delà de tout soupçon soit parfois traduit en « faites des méthodes syllabiques de base ! ». Moi aussi. Dès ma première prise de position sur le sujet en 2006, je dénonçais cette simplification: http://www.lscp.net/persons/ramus/lecture/lecture.html
En 2018, avec quelques centaines d’études de plus qui confirment le même résultat, je dis toujours la même chose: https://www.youtube.com/watch?v=-SfPHLhq9qY&feature=emb_title
Voilà, les scientifiques conseillent, les politiques décident, c’est dans l’ordre des choses.
Après, contrairement à ce que beaucoup d’enseignants croient, la syllabique pure et dure n’est pas un mauvais choix. Étant entendu qu’utiliser une méthode syllabique n’implique pas de faire que cela toute la journée, et de négliger le langage oral, le vocabulaire, la syntaxe, etc. évidemment. Toutes les études montrent que la syllabique est l’un des meilleures méthodes. Mais ce n’est pas la seule. C’est la nuance qui est perdue dans la bataille, et je trouve ça dommage.
J’aimeJ’aime
Si les enseignants croient ceci ou cela, c’est que l’institution, par certains de ses médiateurs, s’est chargée de les conditionner. Je suis passé dans ce crible et j’ai vécu les diverses campagnes promotionnelles de mes supérieurs ou des éditeurs pendant des décennies, tantôt pour Bentolila, tantôt pour les supports en album, tantôt pour le volet analytique… Je n’ai rien contre les méthodes syllabiques pures et j’ai même toujours milité pour que les débutants les utilisent avant toute autre chose. Cela ne m’empêche pas de penser que l’on peut faire mille fois mieux, tant en efficience qu’en agrément de conduite, ou même de réception. Ce propos surprend parfois, mais je trouve surtout que leurs insuffisances se situent d’abord dans le domaine de la maîtrise des syllabes!!!
Les adeptes des méthodes intégratives, selon la terminologie de Goigoux, sont toujours là pour bloquer des initiatives trop ancrées sur les mécanismes phonologiques. De l’autre côté les puristes de la progression phonologique au pas à pas, qui montent en puissance, regardent toujours d’un mauvais oeil une organisation des apprentissages calibrée différemment, effrayés à l’idée de rencontrer un mot dont on n’aurait pas encore étudié au tableau noir les correspondances grapho-phonémiques. Quand vous être pris entre ces deux feux, c’est dur d’émerger.
Pour exemple cet échange, extrait d’une de mes dernières rencontres avec un inspecteur à la pensée aseptisée par les standards et visitant ma classe :
– Vos élèves ont un excellent niveau de lecture. Je ne peux cependant rien dire sur votre méthode, je n’y comprends rien. (sic)
– Mes élèves, semblent avoir compris, eux!
J’aimeJ’aime
Après vous soulevez la question de la transmission et du contrôle des pratiques par les cadres de l’Education Nationale. Vaste sujet, qui me laisse aussi perplexe que vous! Moi aussi j’observe parfois de l’excès de zèle de la part de certains inspecteurs, qui en croyant faire adopter aux enseignants des bonnes pratiques (que j’ai moi-même recommandées), vont en fait bien au-delà de ce que je dis et de ce que la connaissance scientifique autorise à dire et à recommander. Je n’ai pas de bonne solution au problème, si ce n’est de constater que les besoins de formation concernent non seulement les enseignants, mais aussi les inspecteurs et tous les cadres de l’EN.
Moyennant quoi, le système étant ce qu’il est avec toutes ses imperfections, les cadres étant ce qu’ils sont avec la formation qu’ils ont, et le zèle qu’ils ont, il vaut tout de même mieux qu’ils recommandent l’usage de bonnes pratiques éprouvées scientifiquement, que celui de la dernière lubie pédagogique à la mode jamais évaluée. C’est d’ailleurs le meilleur moyen d’éviter les constants coups de balancier que vous dénoncez à juste titre et qui désespèrent tant les enseignants. Car au moins sur un certain nombre de sujets qui ont fait l’objet de nombreuses études et méta-analyses, les connaissances scientifiques sont suffisamment stabilisées pour qu’il n’y ait plus de coup de balancier. Si, ne serait-ce que sur ces quelques sujets, on parvenait à transmettre aux enseignants le consensus scientifique, ce serait déjà beaucoup.
J’aimeJ’aime
Après, une fois qu’un tel résultat de base est établi, on peut aller plus loin. Par exemple comparer l’efficacité des méthodes synthétiques et analytiques (si on pense que ça a encore un intérêt), ou comparer d’autres modalités possibles d’enseigner les relations graphèmes-phonèmes, ou l’intérêt additionnel d’autres ingrédients pédagogiques.
Et bien entendu, ce n’est pas à l’enseignant de faire de telles recherches, ni d’apporter la preuve que ce qu’il fait est efficace. Il existe une infinité de gestes pédagogiques, et il n’est pas possible de tous les évaluer. Ce que l’on peut demander aux enseignants, c’est d’utiliser des pratiques pédagogiques qui s’inscrivent dans l’enveloppe (très vaste) des pratiques recommandées car bénéficiant d’un bon niveau de preuve. Ce qui implique de ne pas ignorer les résultats les plus forts, tout en préservant une large marge de liberté pédagogique.
J’aimeJ’aime
Et oui, il est essentiel que les travaux des chercheurs se nourrissent des interrogations et préoccupations des enseignants. Cela se fait déjà, mais de manière insuffisante.
Le CSEN va très prochainement publier un document qui tente précisément de fournir un cadre à la recherche en éducation, et à la nécessaire collaboration entre chercheurs et enseignants. Des infrastructures sont également à l’étude pour organiser tout ça et stimuler la recherche en éducation. A suivre.
J’aimeJ’aime
Je vous en sais gré. Pour moi, il sera sans doute trop tard : j’ai passé l’âge si l’on puis dire.
J’aimeJ’aime
C’est vrai que jusqu’à maintenant, les chercheurs en éducation travaillaient sur leurs propres lubies : André Tricot, Franck Amadieu, Roland Goigoux, Manuel Muzial, Philippe Mérieux et j’en passe et des meilleurs. Que des gens pas sérieux. Heureusement le CSEN est là….pour organiser tout ça. A suivre…
J’aimeJ’aime
Je ne peux m’empecher de penser a cet article du Lancet , une enorme etude de meta analyse sur laquelle le ministre de la sante a interdit aux medecins francais de soigner leurs malades.
Etude completement bidonnee et frauduleuse.
Dans un journal peer reviewed de l’elite.
Quand les projets (fou furieux) politiques d’une elite psychopathe se font passer pour de la science avec la complicite de scientifiques…je prefere , et de tres loin, l’intelligence, l’experience, et l’empathie des medecins et leurs etudes observationnelles (qui ne veut pas dire informel comme l’article l’ecrit avec malice) du monde reel.
Le labo n’est pas la vie.
J’aimeJ’aime
Effectivement l’étude de Mehra et al. (2020) dans le Lancet était mauvaise, voire frauduleuse, et d’ailleurs elle a été très vite critiquée puis rétractée. Sur cette base, le ministre n’a pas interdit aux médecins de soigner leurs patients, il est juste revenu sur sa décision antérieure d’autoriser la prescription dérogatoire de l’HCQ pour la COVID19, sur la base des études de Raoult encore plus bidonnées et frauduleuses. C’était là la vraie erreur du ministre: autoriser la prescription d’un médicament inefficace et potentiellement dangereux, juste sous la pression d’un gourou médiatique et de ses supporters.
Donc oui, certaines études scientifiques sont mauvaises, et il est hasardeux de fonder une politique publique sur un petit nombre d’études de qualité limitée. C’est bien pour cela que je dis qu’il faut se baser sur de multiples études de bonne qualité qui ont fait l’objet de méta-analyses. De là à en conclure qu’il faut jeter toutes les études scientifiques à la poubelle, et qu’il vaut mieux se fier à l’expérience, l’empathie, l’intuition et le bon sens, hé bien je vous invite à aller jusqu’au bout de votre logique: la prochaine fois que vous allez chez le médecin, exigez qu’il pratique la saignée avec empathie et bon sens, plutôt que de se fier à des études scientifiques!
J’aimeJ’aime
Vous n’avez aucune qualification pour juger les etudes de Raoult: aucune.
Et encore moins de competence medicale: aucune. Rien. Pas plus que la cremiere.
Juger sans competence est la plus haute indignite scientifique.
Quand au ministre il n’a qu’une competence infectieuse tres limitee, etant neurologue.
Mais il a saisi l’oppotunite d’une fausse etude pour INTERDIRE un medicament qui fonctionne tres bien dans l’ensemble du monde.
Son agenda est politique et meme religieux. Luciferien me semble adequat.
Si vous aviez une quelconque capacite de lecture d’etudes medicales, vous le sauriez deja.
Comme les gens eduques le savent deja. Votre parallele avec des saignees de siecles passes est simplement stupide et hilarant.
https://c19study.com/
J’aimeJ’aime
De toute évidence je n’ai aucune compétence et vous sachez mieux que tout le monde, donc arrêtons-là le débat.
Puisque ce médicament fonctionne très bien dans l’ensemble du monde, voyons ce qu’en pensent les agences sanitaires de l’ensemble du monde: https://www.afis.org/Hydroxychloroquine-les-recommandations-des-agences-sanitaires-et-societes
Quoi? Horreur! les lucifériens dominent le monde!
J’aimeJ’aime
Il n’y a pas de debat. Vous n’avez aucune competence en Medecine et encore moins en maladies infectieuses. Insulter le plus eminent medecin en infectiologie non seulement en France mais aussi au monde est infantile et diffamatoire.
Ne vous enfoncez pas plus. La liste des 200 etudes parle d’elle meme.
J’etais majeur de l’Internat de Paris dans ma specialite mais jamais je n’oserais emettre une opinion sur le Dr Raoult. Ce serait stupide et ridicule.
Les agences sanitaires sont completement compromises: que ce soit financierement, politiquement ou religieusement ( et oui je mets les Luciferiens dans cette catgorie corrompue).
Il n’y a jamais eu de debat que dans votre tete: vous n’etes ni competent, ni qualifie.
La science reste la science, et la medecine n’a de comptes a rendre qu’aux malades et certainement pas a des agences de bureaucrates compromis.
https://c19study.com/
Passez cette liste a des gens competents et vous verrez.
J’aimeJ’aime
Pour ceux que ça intéressent, une analyse du site dont vous faites la pub:
https://leadstories.com/hoax-alert/2020/09/fact-check-no-massive-international-study-shows-countries-with-early-hcq-use-had-79-percent-lower-mortality-rate.html
Les auteurs des études qui y sont citées se plaignent qu’on leur fait dire le contraire de ce qu’elles disent. Tous des lucifériens!
J’aimeJ’aime
Pensez-vous qu’une panthéonisation du Dr Raoult de son vivant serait une bonne chose ou un timbre à son effigie sous forme de nouvelle Marianne ? Ciel, le monde entier nous l’envierait !!!!
J’aimeJ’aime
Deux questions qui, à mon sens, contribueraient à une meilleure compréhension des « intérêts » croisés des chercheurs qui se penchent sur les faits éducatifs et les enseignants « affairés à faire ». Ces deux questions, au-delà de leur portée immédiate en lien avec ton texte, me semblent importantes pour cerner « ce dont on parle » lorsqu’on parle de recherches et de pratiques éducatives.
La première porte sur la notion de « méthode », à l’école s’entend. Quelle serait ton acception de « méthode » ? Que recouvre ce terme ? Quelle signification revêt-il dans le cas d’un lecteur-éducateur et dans le cas d’un lecteur-chercheur, impliqués tous les deux dans les apprentissages ?
La seconde est peut-être « plus générale » mais néanmoins indissociable de la première. Que cherche à comprendre ou savoir un chercheur lorsqu’il se penche sur un fait éducatif relatif aux apprentissages ? Que chercheraient les scientifiques « à voir » dans la classe ?
Ces deux questions ne portent pas sur les questions éducatives « macro » (politique publique, économie de l’éducation, évaluation d’un établissement, etc.) mais restent bien dans la limite des interactions d’apprentissage dans la classe.
J’aimeJ’aime
Je n’ai pas trop réfléchi à la notion de méthode, et je ne sais pas si quelqu’un l’a théorisée (sans doute). Mais j’aurais tendance à dire que ce n’est pas vraiment nécessaire pour mon propos. La méthodologie exposée ci-dessus ne présuppose pas une notion de méthode, elle peut s’appliquer à et est déjà utilisée pour tester une très grande variété de facteurs: des médicaments, d’autres pratiques médicales et paramédicales, des politiques publiques, des pratiques pédagogiques, des manuels, des ressources ou du matériel pédagogique, des facteurs plus « macro » comme les moyens des écoles, la taille des classes, ou la formation des enseignants, la disposition des tables ou l’affichage sur les murs. Parmi les pratiques pédagogiques, cela peut être des programmes tout intégré (par exemple Montessori), des grands principes généraux (enseignement explicite ou constructiviste), ou des pratiques très délimitées à un seul apprentissage ou objectif, cela peut être aussi l’attitude et le comportement de l’enseignant, etc. Il n’y a pas franchement de limite.
La seule condition nécessaire pour évaluer, c’est d’être capable d’expliciter suffisamment le facteur que l’on teste et ses alternatives, de manière à être capable de définir une condition dans laquelle ce facteur est présent et une condition contrôle dans laquelle il est absent ou différent. Il faut également que ce facteur soit manipulable ou contrôlable, de manière à s’assurer qu’il est bien présent dans une condition et absent ou différent dans l’autre, et ce pendant une période suffisante pour en mesurer les effets potentiels. Que ce facteur soit une « méthode » ou tout autre facteur est indifférent.
J’aimeJ’aime
Et du coup la réponse à la deuxième question me semble très liée à la première: les chercheurs peuvent s’intéresser à tous les facteurs qui sont susceptibles d’avoir un effet sur les apprentissages, ou sur tout autre variable qu’ils jugent pertinente (par exemple, la motivation, le bien-être ou le comportement des élèves, le climat scolaire, etc.). La plupart s’intéressent aux facteurs qui sont modifiables, et donc sur lesquels on peut jouer dans l’espoir d’améliorer les choses. Mais on peut aussi s’intéresser aux facteurs que l’on ne peut pas modifier (le génome de l’enfant, son passé, son environnement familial et social), notamment parce qu’ils peuvent moduler la réponse de l’enfant aux facteurs modifiables.
J’aimeJ’aime
La methode est moins importante que le contenu.
En l’occurrence le lavage de cerveau de nos petits est effrayant.
A la louche 70% de ce qu’ils apprennent est faux.
J’aimeJ’aime
Vous avez oublié de nous donner le lien vers l’analyse détaillée du contenu des programmes (ou des manuels), conduisant à cette estimation de 70%.
J’aimeJ’aime
Le niveau des élèves est largement déterminé par leur génétique, vous pouvez mettre un singe à la place du professeur ça ne changera rien.
Les traits de consciencieux sont également génétique.
Bref l’éducation ne sert à rien en quelques sorte.
J’aimeJ’aime
Je ne peux que vous recommander de mettre scrupuleusement en application vos croyances à votre propre progéniture: faites éduquer vos enfants par un singe, et ne manquez pas de revenir ici nous exposer les brillants résultats.
J’aimeAimé par 1 personne
Vous savez très bien qu’enfant avec un QI de 75 ne pourra jamais devenir ingénieur… Un enfant avec un QI de 115 oui…
Là est toute la différence,c’est des écarts d’intelligence trop énorme qui entraîne des différences de réussite scolaire puis sociales… C’est largement génétique.
On ne peut pas à ce jour réduire les inégalités intellectuelles, car elles sont déterminés génétiquement…
Laurent Alexandre est l’un des seuls à dire la vérité…
On peut rien faire… Comme quand tu es nain… C’est perdu.
J’aimeJ’aime
C’est pratique de connaître la vérité. Ça évite de se poser trop de questions, de lire et de comprendre les travaux scientifiques, ouh la la, cette méthodologie, ces statistiques, c’est compliqué! Et puis ces résultats nuancés, c’est pas clair, on y comprend rien, que faut-il croire à la fin?
JE VEUX CROIRE A UN TRUC SIMPLE! HELP, LAURENT ALEXANDRE!
Pour ceux qui ne veulent pas seulement croire mais sont prêts à affronter un peu de complexité, voici quelques éléments sur:
– dans quelle mesure le QI prédit la réussite scolaire, professionnelle et d’autres choses;
– dans quelle mesure le QI est influencé par des facteurs génétiques;
– dans quelle mesure le QI est influencé par des facteurs environnementaux;
– dans quelle mesure la réussite scolaire est influencée par des facteurs génétiques et environnementaux.
J’aimeJ’aime
Vôtre ton ironique et méprisant ne changera pas la réalité des choses.
Les gens qui ont un QI de 75 échouent socialement, à cause de leurs mauvais tirage à la loterie GÉNÉTIQUE.(Kathryn Paige Harden)
C’est statistiquement vérifiable.
La triste vérité est que vous psychologues vous n’avez absolument aucune solution à proposer à ces gens…
C’est GÉNÉTIQUE… 😔
J’aimeJ’aime
Le livre « La loterie génétique » de Paige Harden (bientôt traduit en Français) est excellent. Mais il est important de le lire au-delà du titre pour savoir qu’elle ne tient absolument pas ce genre de discours univoque et caricatural.
J’aimeJ’aime
Je sais que Paige Harden ne tient pas mon discours, j’ai cité son livre car il parle de la chance génétique…
Exactement la problématique.
Ma mère est deficiente intellectuelle évidemment que j’ai un regard triste et noir sur le sujet… Je connais la situation et il n’y a aucune solution à ce jour. C’est bien la vérité.
J’aimeJ’aime
Maintenant c’est l’argument par l’anecdote.
Prenons un cas extrême avec causalité génétique parfaitement établie: les enfants avec trisomie 21. Pendant longtemps on ne leur a rien enseigné parce qu’on ne les pensait pas capables d’apprendre. Maintenant il y a des programmes d’éducation pour eux, ils peuvent apprendre plein de choses, y compris à lire, et ils peuvent être scolarisés dans des écoles normales. Bien sûr ils resteront toujours trisomiques, et leur QI n’atteindra pas des sommets. Mais ils peuvent néanmoins progresser significativement en fonction de la manière dont on les éduque. Leur trajectoire développementale est contrainte mais pas déterminée par leurs gènes.
J’aimeJ’aime
Ce n’est pas une anecdote Mr Ramus , c’est le lot de milliers de famille en France qui ont dans leur entourage une personne à faible QI.
C’est clairement difficile. Pour un emploi, pour la scolarité…
La génétique determinent leurs succès dans la vie… Et les maintiens statistiquement en bas de l’échelle sociale… C’est la réalité.
Un enfant trisomique doit avoir en moyenne un QI de 50… Évidemment qu’il peut apprendre à lire, c’est un potentiel l’intelligence… Mais avec un plafond.
Nous n’avons pas tous le même plafond.
Imaginez la différence de puissance cérébrale entre un QI de 75 et un QI de 125… C’est cela le problème dénoncer par Laurent Alexandre, il y a toujours un Gap génétique irréversible…
Ce gap est responsable des inégalités sociales et scolaires … C’est le serpent qui se mort la queue…
D’ailleurs j’ai une question comme vous êtes connu sur le sujet du QI et que vous fréquentez des enseignants…
Est ce que la majorité des enseignants ont conscience des différences d’intelligence d’origine génétique entre les élèves ?
Car les fréquence alléliques de l’intelligence explique de plus en plus la Variance dans l’éducation.
Un jour on va arriver à un truc énorme…
J’aimeJ’aime
Bonjour, merci pour cet article très intéressant. Ça nous invite à rester humble et nuancé 🙂Avons nous actuellement une idée en pourcentage de la part de l’école dans le développement de l’intelligence.
Autrement dit, dans 50% d’environnement, quel est le pourcentage de l’école ? 🙂
Signé un enseignant qui ose croire servir à quelque chose 😅
J’aimeJ’aime